EcmaScript6 + power-assert でテストを書く
この記事はJavaScript Advent Calendar 2014の15日目の記事です。
さてさて、EcmaScript6に対する機運が高まっている中で、ES6の新機能の紹介記事が出てきておりますが、ES6が使えるブラウザはまだ浸透しておらず、使おうとするならばTraceur Compilerや6to5といったトランスパイラを利用せざるを得ないというのが現状です。
これらのトランスパイラも実際のプロダクトで使おうとするとまだそこまで実績がないし、いきなり本番で使うという訳にいかない人達が多いかと思っています。
ただし、ES6には慣れておきたい、、、ES6の新機能(let, template-string, arrow function, generator, promise, etc...)を使ってみたい、、、
ならばせめてテストだけでもES6で書こうじゃないか、いずれES6が来た時に文法や新機能だけでも慣れておくために!!
というわけで、mocha x power-assert x traceur でテストを書けるようにするライブラリを作りました。
yosuke-furukawa/espower-traceur · GitHub
mocha x power-assertでテスト書いてる人達は多いと思いますが、それの前段階でtraceur-compiler使ってES6からES5にトランスパイルした上でテストを実行してくれます。
Getting Started
まずはespower-traceur, power-assertをインストール
$ npm install espower-traceur power-assert -D
mochaがインストールされていなければmochaをインストール、ここではglobalに入れるけど、npm testで呼び出すならglobalに入れる必要はありません。
$ npm install mocha -g
テスト対象のファイルを書く
おもむろにこんな感じのコードを書いて、person.jsとでもしておきましょう。
(function(global){ "use strict"; var Person = function(name, age){ this.name = name; this.age = age; }; Person.prototype.getAge = function() { return this.age; }; Person.prototype.greet = function() { return "Hello! I am " + this.name + ". My age is " + this.age; } if (module && module.exports) { module.exports = Person; } else { global.Person = Person; } }(typeof global !== 'undefined' ? global : this));
やってることは簡単で、Personクラス作って、年齢をとったり、挨拶したりするだけです。ここまではまだES5の世界ですね。
じゃあこれをテストするコードをES6で書いてみましょう。
テストコードを書く
こんな感じでmochaで書いて、testフォルダ下にtest/person_test.jsとでもしておきましょう。
// let 変数で宣言するのがES6式 let assert = require("power-assert") let Person = require("../person") // arrow 関数でdescribeを書く describe("Person", ()=>{ let name = "Alice" let age = 4 let alice = new Person(name, age) it("alice get age", ()=>{ assert.equal(alice.getAge(), age) }) it("alice greet", ()=>{ // template stringで文字列埋め込みする assert.equal(alice.greet(), `Hello! I am ${name}. My age is ${age}`) }) })
と設定したら後は、mochaから espower-traceur/guess を呼び出せばOK。
注意:ここでは、describeやitの引数にarrow関数を使いましたが、mochaのコンテキスト変数(this)を利用する場合にはarrow関数を利用するのは避けましょう。arrow関数のthisは常にレキシカル(bind(this)された状態)になります。
テストを実行してみる
$ mocha --require 'espower-traceur/guess' test/*.js
結果

万が一ミスマッチの値があった場合は以下のようにpower-assertが値を表示してくれます。

【翻訳】リッチなWebアプリケーションのための7つの原則
はじめに
この話はGuillermo Rauch氏が書いたhttp://rauchg.com/2014/7-principles-of-rich-web-applications/ という記事の翻訳です。許可を得て翻訳しています。
ここ最近Web業界を賑わしているSingle Page Applicationの必要性、HTTP2/SPDYといった技術、リアクティブプログラミングやIsomorphicデザインという考え方について包括的にまとめたすごく良い記事になっております。
最初に断っておきますが、ものすごく長いです。各セクションがわかれているので時間がない方はセクションごとに書かれたtl;DRとまとめを読むだけでも参考になるかと思います。
ちなみに明日のNode学園祭には、本記事を記述したGuillermo Rauch氏が見えるので、そこで詳しく聞いてみるのもいいのではないでしょうか。
リッチなWebアプリケーションのための7つの原則
これは2014年の8月に開催されたBrazilJSで話したプレゼンテーションを元にまとめたものです。私がUXやパフォーマンスに関して最近ブログに書いて まとめたアイデアのいくつかで構成されてます。
UIコントロールをJavaScriptで行っているウェブサイトのための、7つの実践可能な原則を紹介しようと思います。この原則は私がWeb開発者として経験したことに基づいているだけじゃなく、World Wide Webの長期ユーザーとしての経験から作られています。
JavaScriptはフロントエンド開発者にとっては無くてはならないツールになっています。その使用方法はサーバーやマイクロコントローラーなど、色んな領域に拡張されています。
しかしウェブにおいてJavaScriptの正確な役割や利用方法についてはたくさんの疑問や謎があります。多くのフレームワークやライブラリ作者においても同じことが言えます。
- historyやnavigationやpage renderingといったブラウザの機能をJavaScriptで置き換えたほうが良いのか?
- backendで多くの処理をするのはオワコンなのか? それとも全てのHTMLをレンダリングするべきなのか?
- Single Page Applicationは未来なのか?
- JSはサイトのページを拡張するためのものなのか、アプリケーションとしてページをレンダリングするためのものなのか?
- PJAXやTurboLinksのようなテクニックは使ったほうがよいのか?
- ウェブサイトやウェブアプリケーション感のはっきりした違いとは何なのか? そもそも違いなんてあるのか?
これらの疑問に対して以下のように回答してみました。私のアプローチはUXの観点からJavaScriptの利用方法を調査する、という方法を取りました。特に、エンドユーザーにとって興味のあるデータを取得させるため、どうやって時間を短縮しようとしているのかといったアイデアに強くフォーカスを当てて調査しました。ネットワーク基礎を初めとして、未来予測まで幅広く記述しました。
- サーバーがページをレンダリングするのは任意ではない (必須である)。
- ユーザー入力に迅速に対応しよう
- データの変更に反応しよう
- データ変更をサーバーとともにコントロールしよう
- historyを壊すべきじゃない、historyを拡張しよう
- コードの更新をPushしよう
- 振る舞いを予測しよう
1. サーバーがページをレンダリングするのは任意ではない (必須である)。
tl;DR: サーバーレンダリングはSEOだけのものじゃなく、性能を向上させるためのものです。JavaScriptやCSS、APIリクエストを取得する時にラウンドトリップが起きる事を考慮して設計すること。将来的にはHTTP 2.0でリソースをサーバープッシュする事も検討しておくこと。
これまで、このトピックは一般的に対立構造(VS構造)として語られてきました。例えば、 "Server Side Rendered Apps vs Single Page Apps"といったような形です。もし我々がUXや性能をベストまで最適したいと思ったら、サーバーサイドレンダリングとSingle Page Appsのどっちかを取ってどっちかを諦めるのは良いアイデアとはいえません。
その理由はわかりやすく単純です。インターネットを介して送信されたどんなページにも理論的なスピードの限界があるからです。この限界はStuart Cheshireによって書かれた有名なエッセイ、 "It's the latency, stupid"によって説明されています。
StanfordからBostonまでは4320kmある。
真空状態の光の速度は 300 x 10^6 m/s.
ファイバーの中での光の速度は大雑把に言うと真空状態の 66%。
ファイバーの中での光の速度は 300 x 10^6 m/s * 0.66 = 200 x 10^6 m/s
ボストンへの片道で遅延は 4320km / 200 x 10^6 m/s = 21.6ms.
ラウンドトリップタイムはBostonから戻るまでに43.2ms.
現在のインターネット環境でStanfordからBostonにpingを送った時は大体85ms
そのため: インターネットのハードウェアは光の速度の2倍くらいかかることになる。
BostonとStanford間の85ms のラウンドトリップタイムは将来的に改善されていくでしょう。もしかしたら今すぐにでも実験すれば改善は見られるかもしれません。しかし、BostonとStanford間にはどんなに速くなったとしても約50msほどの理論的な限界値があるということに注意しなくてはなりません。
ユーザーのコネクションにおける帯域幅の制限はものすごく改善されるかもしれません、それが堅調に改善されたとしても、latencyの指している針(限界値)は全く動かないでしょう。ページ上のなんらかの情報を表示しようとする際に。ラウンドトリップ自体の回数を最小化する事が重要になるでしょう。
特に素晴らしいUXやレスポンシブさを提供するためには考えるべきです。
これは特に<script>や<link>タグ以外のマークアップが存在しない、空のbodyタグで構成されたJavaScript駆動のアプリケーションが起動する時に考慮する必要がある問題です。この種類のアプリケーションは "Single Page Application" とか "SPA" の名前で受け入れられています。その名前が示す通り、一つのページしか存在せず、クライアントサイドのコードによって残りの部分を表示します。
URLが打ち込まれたり、linkを辿った際に、http://app.com/orders/にユーザーがページ遷移する、というシナリオを考えてみましょう。その瞬間からあなたのアプリケーションはリクエストを受けて、処理が始まります、そのページを表示しようとするのに重要な情報は既に持っています。例えばdatabaseからの命令をpre-fetchしたり、レスポンスにそれらの情報を含めることができます。ほとんどのSPAの場合、ブランクのページと<script>タグがその代わりに返されます。それからさらに一回のラウンドトリップが行われて、スクリプトの内容が取得されます。さらに、もう一度ラウンドトリップが発生しレンダリングするためのデータが取得されます。
ほとんどの開発者は意識的にこのトレードオフを受け入れています。なぜなら彼らはその複数回のネットワークホップがたかだか一回しか発生しない事を確認しているからです。つまり、彼らのユーザーはscriptやstylesheetのレスポンスヘッダーに適切なキャッシュ情報を埋め込んでいるため、キャッシュにヒットされれば毎回のホップは発生しない事になります。一度だけロードされ、ほとんどのユーザー操作(他のページに遷移するといったような操作)をハンドリングできれば、追加のページやスクリプトのリクエストを発行する必要はありません。これが受け入れ可能なトレードオフであるということは一般的に認識されています。
しかしながら、キャッシュがあったとしても、scriptパースや評価にかかる時間が考慮された際にパフォーマンス上の障害になることがあります。 "jQueryはMobileにはでかすぎじゃね?" という記事では、jQuery単体であっても、mobile browserが確認するためには何百ミリ秒のオーダーがかかることが記述されています。
不幸なことに、scriptがロードされている間、ユーザーに対して何のフィードバックも帰ってこない事があるのです。この結果、ブランクのページが表示され、直後に全ページがロードされて描画されます。
最も重要な事として、我々開発者はインターネットデータ通信 (TCP) の開始が遅いということを常に意識しているわけではありません。TCPの開始が遅いことによって一回のラウンドトリップで全てのscriptをfetchされるようなことはまずありません。それだけじゃなく、さらに悪い状況を作ることもあります。
TCP接続は初期ラウンドトリップのハンドシェイクとともに開始されます。もしあなたがSSLを使っているのであれば、2回のラウンドトリップ*1が行われるでしょう。データ送信がサーバーから開始されるのは、ゆっくりと段階的に行われることに成ります。
輻輳制御のメカニズムはTCPプロトコルの中ではスロースタートと呼ばれています。TCPプロトコルはデータを送る際に一度に送るセグメントの数を徐々に増やして送ります。SPAにとってこの仕組みには2つの深刻な影響があります。
1. 巨大なスクリプトがあると予想よりもはるかにダウンロードに時間がかかることになります。
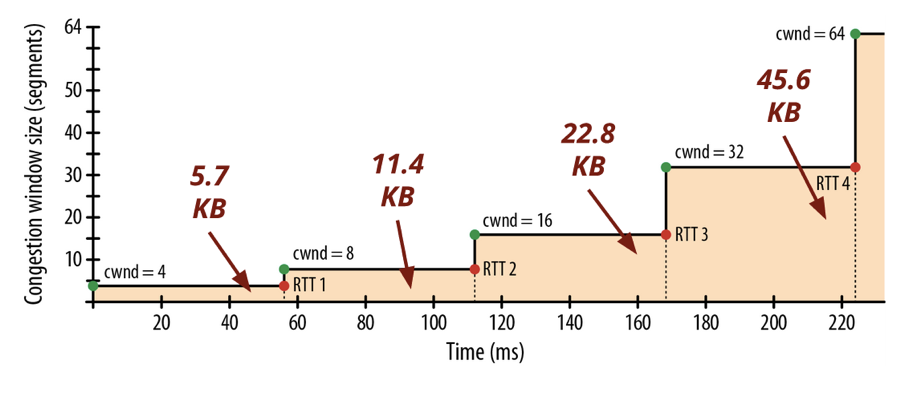
Ilya Grigorikが書いた"ハイパフォーマンスブラウザネットワーキング"で説明されている通り、"クライアントとサーバー間で64KBのスループットを届けるだけでも4回のラウンドトリップと何百ミリ秒ものレイテンシーが発生する。"事になでしょう。この例では、LondonとNewYorkの間の長いインターネット接続が考慮されているが、TCPが最大パケットサイズに届くようになるまでに225msかかると言われています。
2. TCPスロースタートの法則は初期ページのダウンロードにも適用されます、初期ページには全てのページの中で一番重要な"ページをレンダリングするのに必要な情報"があります。 Paul Irishはかれの発表資料、"Delivering the Goods"の中で、初期の14kbが如何に重要かを語っています。サーバーがラウンドトリップ内で送信できるデータ量に関するわかりやすいイラストを見て下さい。
このウィンドウサイズに合わせてコンテント*2を配信するウェブサイトはかなりレスポンシブに見えることでしょう。実際、高速なサーバーサイドアプリケーションを書いている多くの開発者にとって、JavaScriptは不要であると考えられていたり、控えめに使われている事があります。もしアプリケーションが高速なバックエンドとデータソースとユーザーに近い場所にサーバーがある(CDNを利用している)場合、このバイアスはかなり強くなります。
コンテントの表示が高速化され、補えるようになれば、サーバーの役割はアプリケーション特化なものになっていくでしょう。そのソリューションは常に"サーバーで全ページをレンダリングすればいい"という程に単純にはなりません。
いくつかの場合において、本質的じゃないページのパーツは初期レスポンスから外して、クライアントによって後で取得させた方がより良くなるでしょう。いくつかのアプリケーションは迅速にレスポンスを返すためにそのページの外枠を先にレンダリングしようとします。そうした後で並列にページの異なる部分をfetchします。これは遅くてレガシーなバックエンドサービスの場合には素晴らしい反応を見せるでしょう。いくつかのページにおいて、"above the fold(スクロールしなくても見えるページ)"のプリレンダリングをしておくことは有効な選択肢と言えます。
セッション、ユーザー、URLごとにサーバーが持っている情報に基づいてscriptやstyleの存在意義を評価する事はかなり重要です。例えば、orderをソートするスクリプトは/settings ページにあるよりも /orders ページにだけ存在するほうがいいでしょう。
直感的じゃないかもしれませんが、"構造を作るCSS"と"skinやテーマを決めるCSS"間の違いを作っておいたほうが良いかもしれません*3。前者はJavaScriptコードから利用されるため、ロードされるまでブロックされるべきですが、後者は非同期でロードされたほうが良いでしょう。
ラウンドトリップが複数回発生することによる障害を受けないSPAのシンプルな例として、StackOverflow in 4096という名前のStackOverflowのクローンがあります。4096バイトだとTCP接続の最初のハンドシェイクラウンドトリップの後で理論的には配信されることができます。これはレスポンスの中で全てのアセットをインラインにすることによってcacheabilityを犠牲にして実現されています。SPDYもしくはHTTP/2のサーバープッシュがあれば、理論的にはクライアントのコードをキャッシュ可能な状態でシングルホップで配信する事ができるようになるでしょう。当分の間はページの一部分もしくは全てのレンダリングをサーバーでやることが複数ラウンドトリップを回避するための一般的なソリューションになるでしょう。
ブラウザとサーバー間でレンダリングするコードを共通化でき、scriptsとstylesをロードするツールを提供するシステムはウェブサイトとウェブアプリ間のラフな違いをなくしていくでしょう。両者とも同じUXの原則に従うことになります。ブログとCRMは基本的にそんなに違いはありません。両方共URLがあってnavigationがあり、ユーザーにデータを表示します。クライアントサイドの機能に強く依存しているspreadsheetのようなアプリケーションでさえ最初にユーザーにデータを表示する必要があります。つまりネットワークのラウンドトリップ回数を最小にすることが最も重要になるという事です。
パフォーマンスに関してのトレードオフによって、ウェブは複雑さをどんどん増していっています。複数ラウンドトリップにも非常に関係があるように見えます。
JavaScriptとCSSによるテクニック、Tips*4は時間とともに追加されていました。そういうテクニックの人気や評判も時間とともに増加してきました。
今後はそういったテクニックには別な方法があることを理解できるでしょう。SPDYやQUICに見られる改善中のプロトコルによってこれらのいくつかは解決され、さらにアプリケーションレイヤーにも多くの利点を発生させる事になるでしょう。
初期のWWWやHTMLの設計に関する初期の議論のいくつかを参考にするとこれを理解しやすくなるでしょう。特に1997年の<img>タグをHTMLに追加する事を提案しているこのメーリングリストのスレッドの中で Marc Andreessenが高速に情報を提供することの重要さについて度々話をしています:
"もしもドキュメントがその場その場で断片化されなければならないのであれば、複雑さを生むことになってしまうだろう、そして例えそれらが限定的だったとしても、私達はこの複雑な方法で構造化されたドキュメントの性能にぶつかることを体験し始めることは明らかだ。これは本質的にWWWのシングルホップの原則をドアの外に投げ出している (IMGタグもそれをすることになる)。本当に我々はそれをしたいのかどうか胸に手を当ててみたらどうだろうか?"
2. ユーザー入力に迅速に対応しよう
tl;DR: JavaScriptを利用すればネットワークレイテンシーを隠せるようになります。これをデザインの原則として適用すれば、あなたのアプリケーションから"ロード中..."のメッセージやスピナー(ぐるぐる)を削除することができるようになるでしょう。PJAXもしくはTurboLinksはこの"the perception of speed" (スピードの錯覚) を使って改善するチャンスを失ってしまうでしょう。
最初の原則はあなたのウェブサイトに対してレイテンシーを最小化することの考え方に関するものでした。
とは言っても、サーバーとクライアント間を往復する回数を最小化するためにどれだけ努力を惜しまなかったとしても、どうにもならない事があります。ユーザーとサーバー間の距離によって得られる理論上最小のラウンドトリップタイムが発生してしまうことは避けようがありません。
貧弱だったり予測できないようなネットワークの品質も重大な事項の一つになるでしょう。もしネットワーク接続がそこまで品質の良いものじゃなかったとしたら、パケットの再送が発生するでしょう。結局、取得するのに何回もラウンドトリップが発生してしまうような結果になる事は予測できます。
UXを向上する事に対してJavaScriptの最適な強みはこの部分にあります。クライアントサイドのコードはユーザーインタラクションを強く惹きつけておくことで、このレイテンシーの問題を隠すことができるようになります。スピードの錯覚を作ることができます。人工的にレイテンシーが存在しないように見せようとすることもできます。
ベーシックなHTMLウェブをちょっとだけ考えてみましょう。ハイパーリンクまたは <a>タグを通してドキュメント同士をつなぐことができます。リンクがクリックされた時、ブラウザは予期できないほど時間がかかる可能性があるネットワークリクエストを発行し、そのレスポンスを取得し、処理し、新しい状態に最終的に遷移します。
JavaScriptではユーザーの入力後に即座に実行する事も、少し送らせてから楽観的に実行する事もできます。リンクやボタンの上でクリックした時に、ネットワークを使わずに即座に反応するという事もできます。有名な例としてはGmail (またはGoogle Inbox)が挙げられます。emailをアーカイブするとUI上で即座に反応が返ってきます。その後、非同期に処理をサーバーに送っています。
フォームの場合、submitしたあとでレスポンスとしてHTMLを待つ代わりに、ユーザーがenterを押したあとで即座に反応することが可能です。より良い例として、Google Searchのような動きが当てはまります。下矢印キーを押し続けるとユーザーに即座に反応を返します。
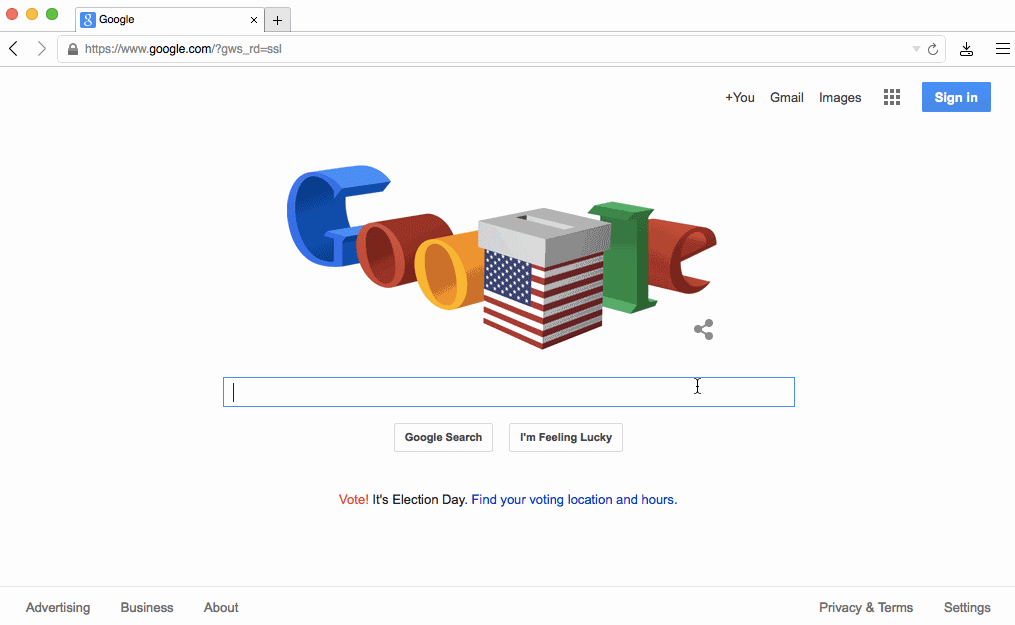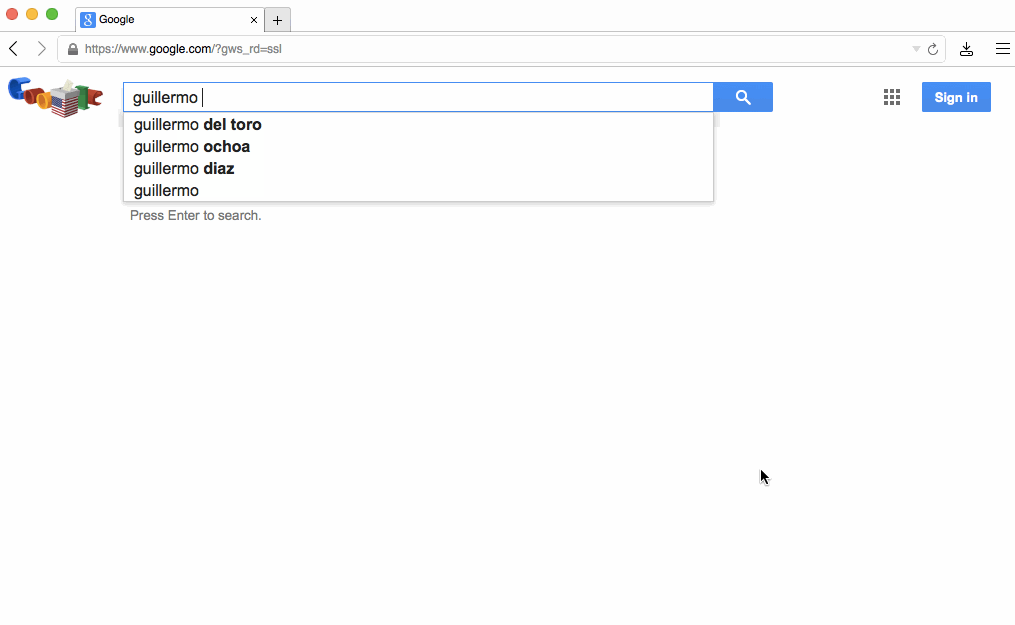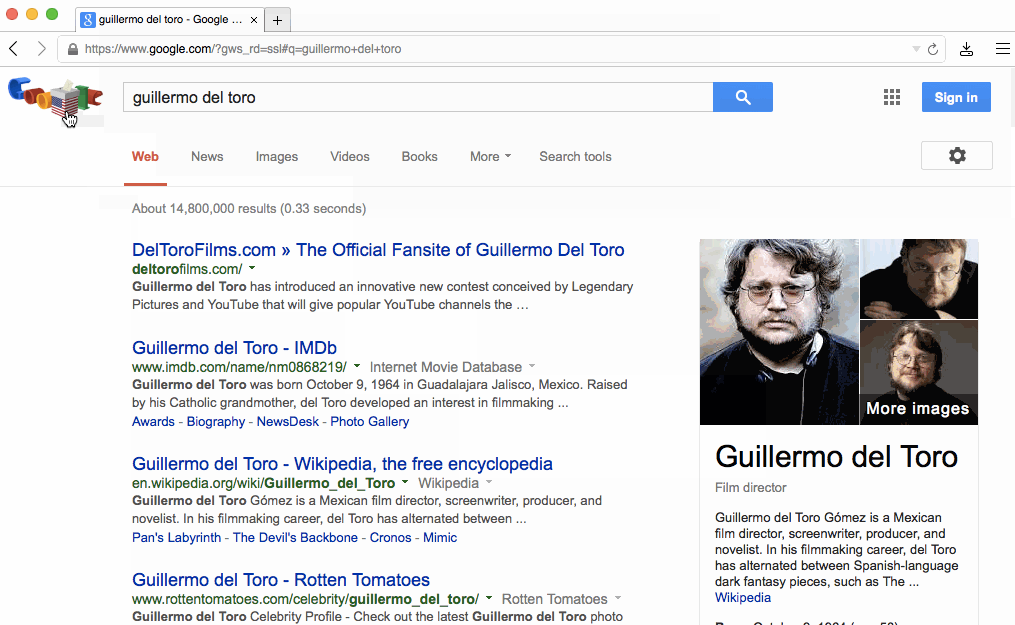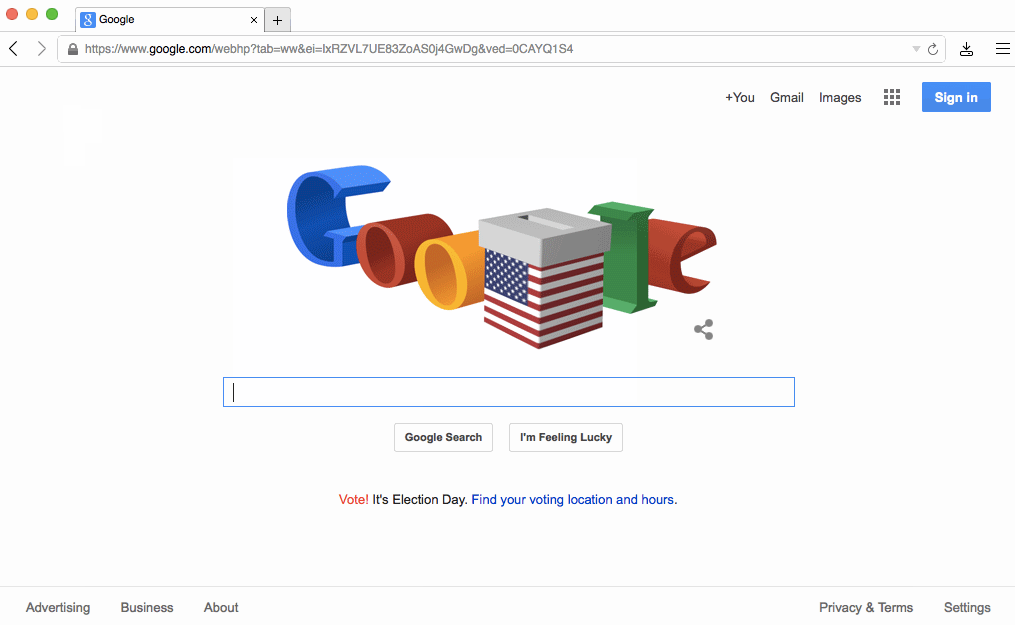
その特別なふるまいはlayout adaptationと呼ばれるものの例です。基本的なアイデアはページの初期状態が次の状態のレイアウトについて"知って"おり、遷移する前にそのページに入れるべきいくつかのデータがあれば可能になります。データを事前に持つことは"楽観的"と言われています、なぜなら入力によってはデータが全く来ない時にかわりにエラーが表示されるリスクがあるからです。しかし、そのような場合は明らかに少ないと言えるでしょう。
Googleのホームページは特にこの試みに適しています。なぜならこの進化は私達が議論してきた最初の2つの原則を解説するからです。
最初に、www.google.comへTCP接続をした時のpacket dumpを解析すると、リクエストが発行された後で一度に全体のホームページを送っていることが確認できると思います。接続をクローズするまで含めた全体はSan Franciscoにいる私には64msかかります。初めから今までそういう傾向にあります。
{kind=link}
2004年の後期にGoogleはas-you-typeサジェスト機能(キーボートをタイプした瞬間から検索する機能((Gmailのように20%プロジェクトとして作られました)))を提供し、JavaScriptの利用方法を開拓しました。これは後にAJAXを作るきっかけになりました。
ここでちょっとGoogle Suggestを見てみましょう、あなたがタイプした瞬間にページのリロードや待ち時間もなく即座にサジェストされる単語がアップデートされることに注目してください。Google SuggestやGoogle MapsはAdaptive Path社がAjaxと名づけた技術を使って Web アプリケーションの新しいアプローチを示した2つの例です。
2010年にGoogleはInstant Searchを紹介しました。InstantSearchはJSをフロントにおいてキーを押した瞬間にページリフレッシュをまるごとスキップさせて、"検索結果" レイアウトに即座に遷移するようにしていました。ちょうど上の画像の例のとおりです。
layout adaptationのもう一つの有名な例があなたのポケットにも入っているかもしれません。初期からiPhone OSはアプリケーション作者に default.png の画像を提出させます。これは実際のアプリケーションがロードされるまでの間に即座にレンダリングさせるためです。

この場合、OSがネットワークレイテンシーによる遅延だけじゃなく、CPUによる遅延を考慮し、それを補うために行っています。アプリケーションがロードされる前に初期ロードを早くするためにレイアウト画像を見せることはハードウェア本体の制約としても極めて重要だと考慮されています。
しかしこの技術がマッチしないシナリオも存在します。レイアウトがストアされた画像にマッチしない時、例えば全然レイアウトが違うログイン画面に遷移してしまうといった場合にマッチしません。その影響がどのくらいのものなのかを分析した結果がMarco Armentによって2010年に提供されています。
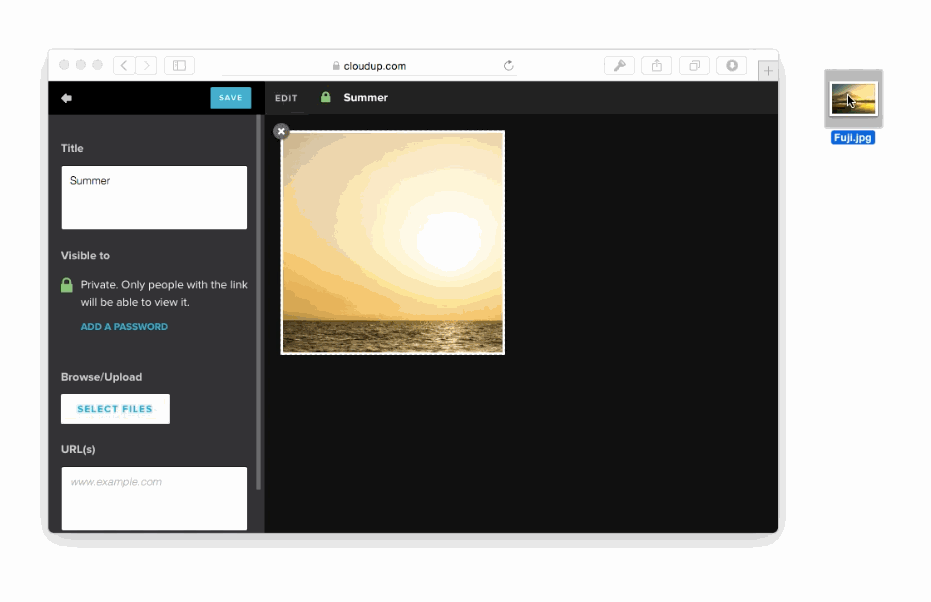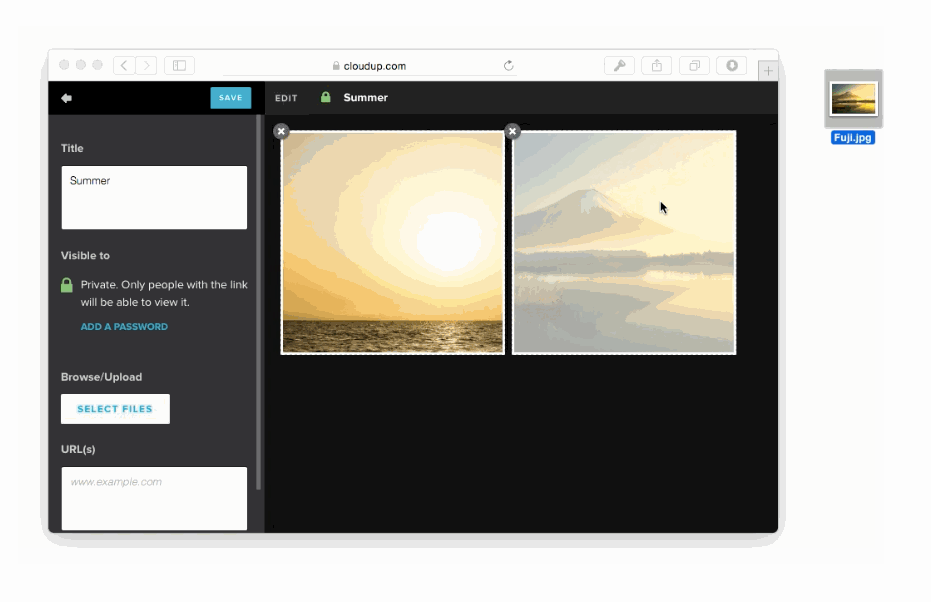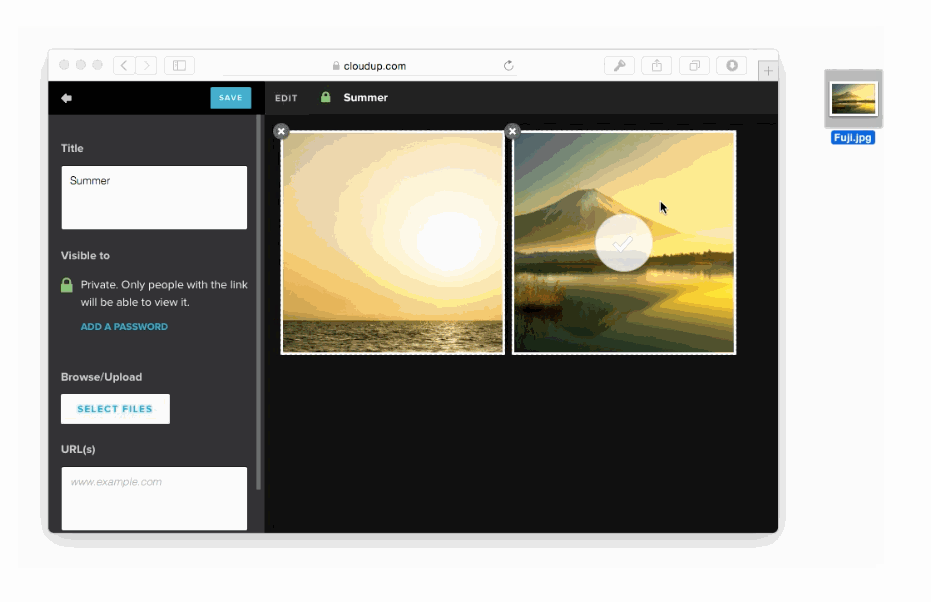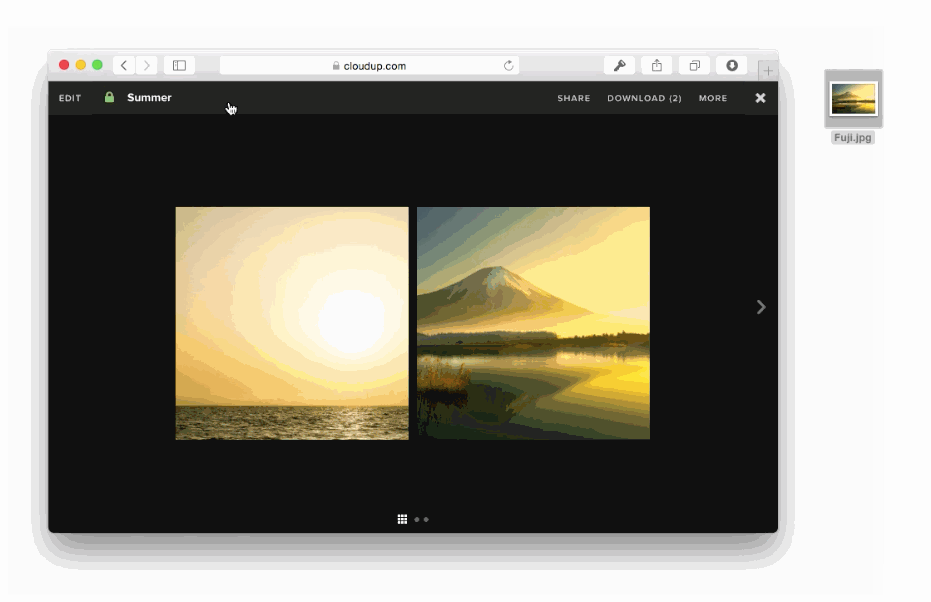
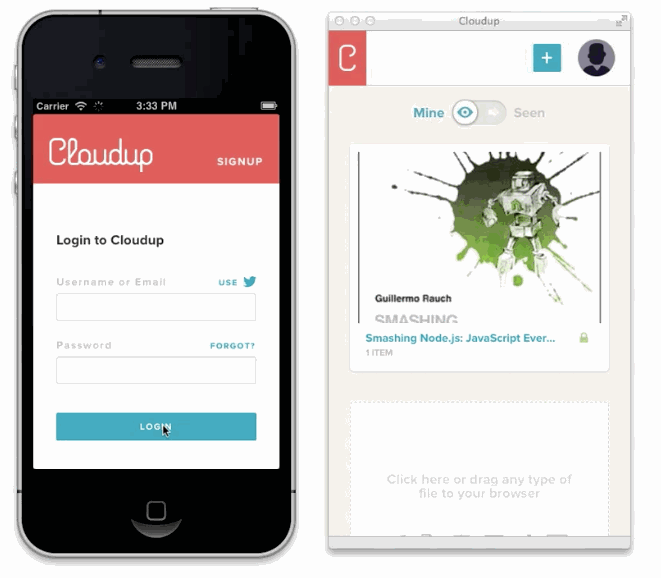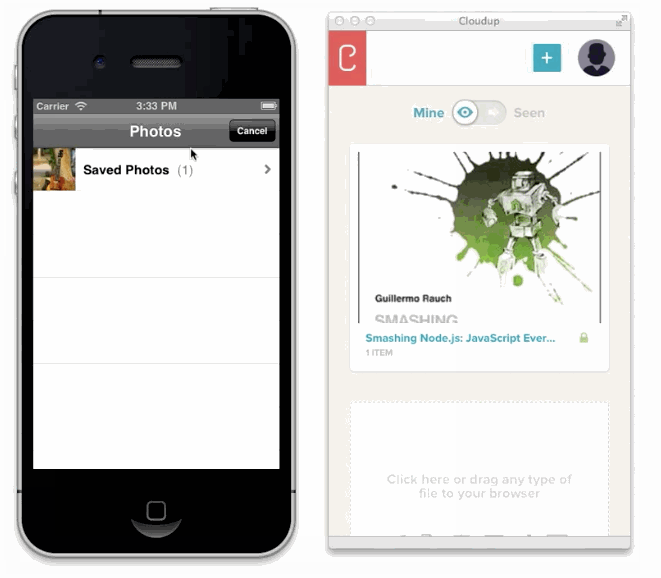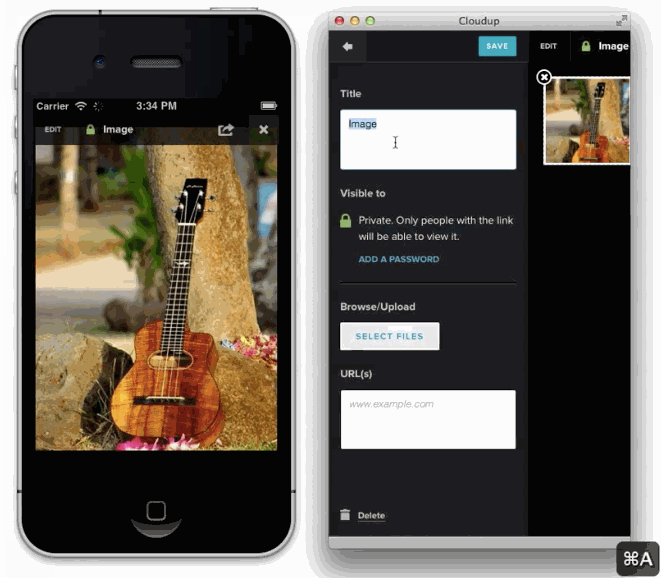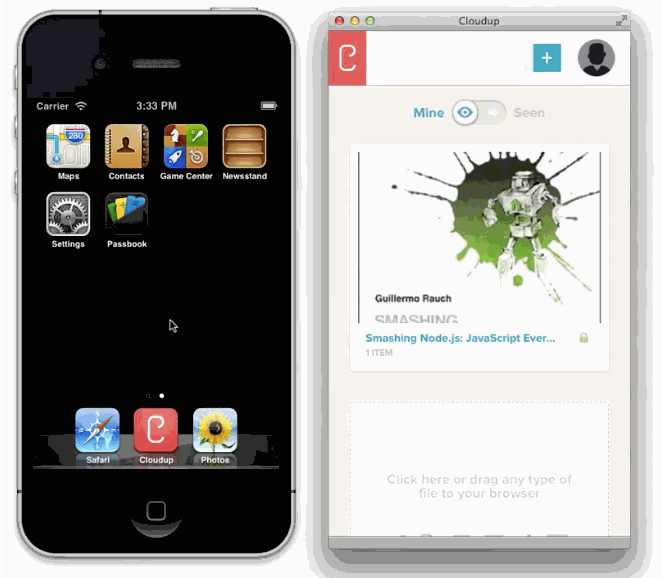
JavaScriptによって入力フォームとクリックとデータ送信が強化される例があります、ファイル入力です。
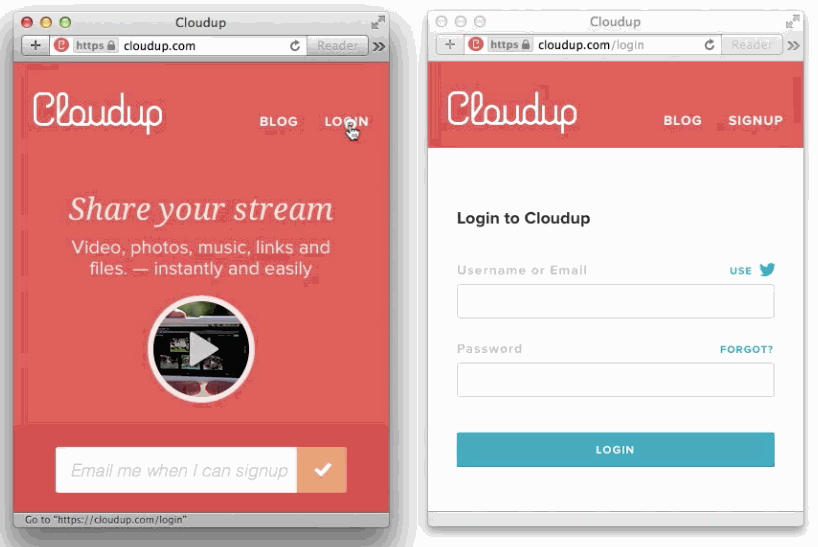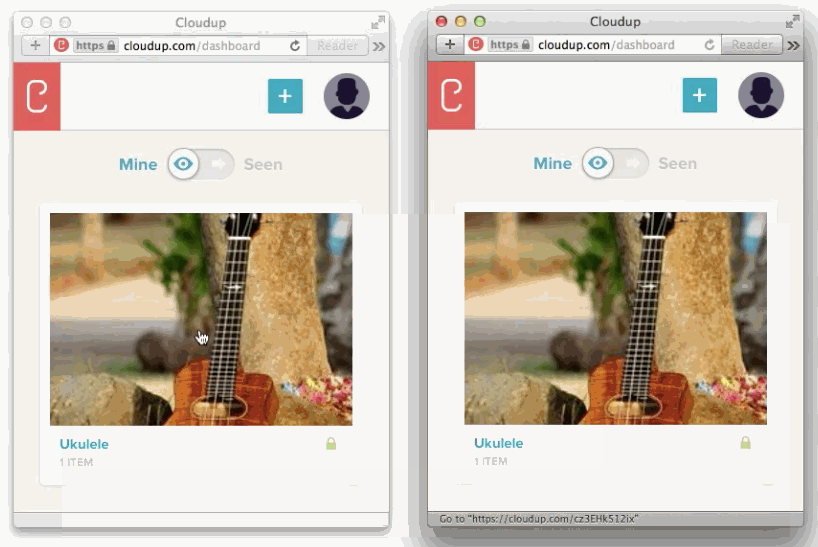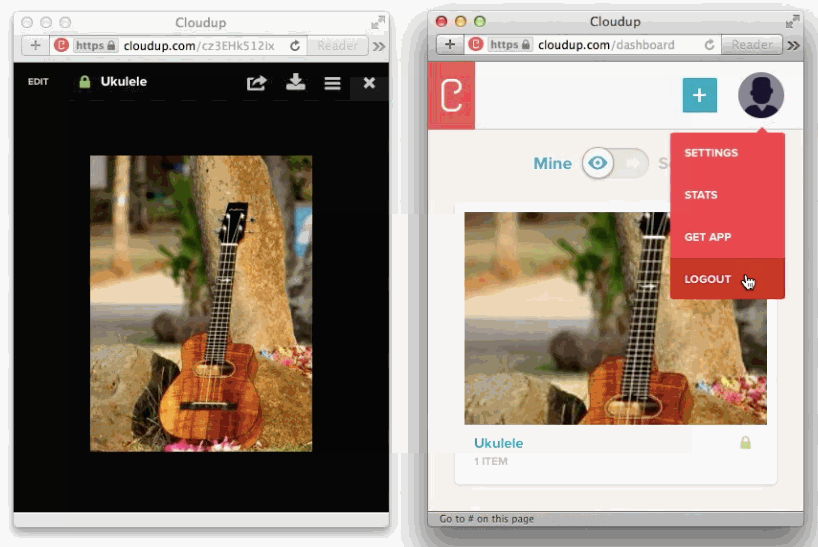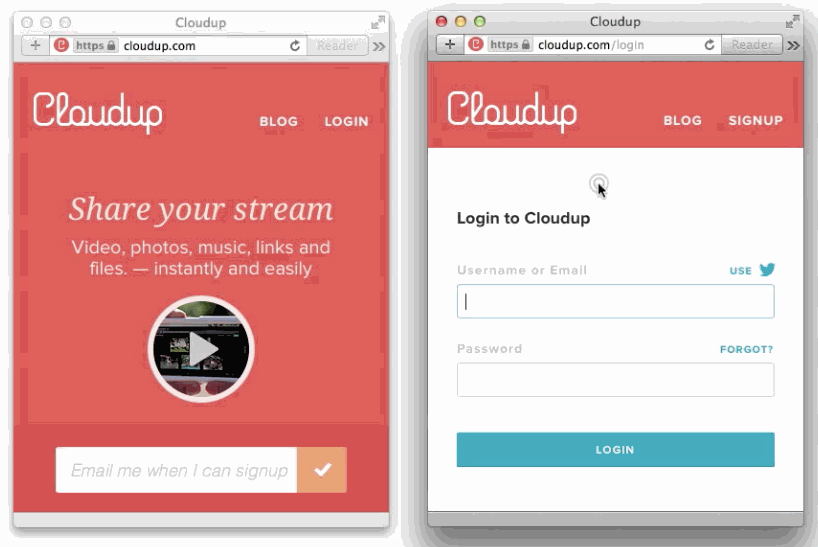
様々な方法でユーザーのアップロードを処理することが可能です。ドラッグアンドドロップやcopy & paste、ファイルピッカーといった方法で処理することが可能です。新しいHTML5 APIに感謝しなくてはいけません。私達はまるでアップロードされたかのようにコンテントを表示することができます。この例はCloudupで画像アップロードをしている最中の動きです。thumbnail画像が生成され、即座にレンダリングされていることに注目してください。
これまでの例において、私達は感覚的にスピードが上がったかのように見せることができます。ありがたいことに、これが良いアイデアだとする沢山の証拠があります。素早く手荷物を扱わなくても、敢えて手荷物受取り所までの距離を増やす事で時間をかけてヒューストン空港でクレームの数を減らした手荷物受取所の例を考えてみてください。
こういう敢えて遅くするようなアイデアのアプリケーションはUI上ではとても深淵な実装をしなければなりません。私は"ロード中を示すインジケータ"とかスピナーがほとんど表示されてはいけないと思っています。生のデータを持ってアプリケーションを遷移する時は特に表示するべきじゃないと思っています、詳しくは次のセクションで触れます。
スピードのごまかしはUXには時に有害になるシチュエーションがあります。支払いフォームやログアウトリンクのような例を考えてみてください。それらに対して楽観的なふるまいをすると、終わっていなかったとしてもユーザーに全てが終わったと通知してしまいます。その結果、ネガティブな体験になってしまう可能性があります。
そういうケースの場合では、スピナーや"ロード中を表すインジケータ"の表示を繰り返すべきでしょう。こういうケースではユーザーはレスポンスが即座だったかどうかはそこまで気にしません。ちゃんと終わってから結果をレンダリングするべきです。Nielsenによる研究結果によれば:
レスポンス時間に関する基本的なアドバイスは MillerやCardらが行っていた研究と13年前から今までほとんど変わっていない。
ユーザーからみて"システムが即座に反応している"と感じるのは大体0.1秒までである。つまり、0.1秒以内であれば、結果を表示するまでに特別なフィードバックは必要ないという事を意味している。
ユーザーがちょっと遅いなと感じる限界は1.0秒までだ、それ以上ではユーザーが遅延したと感じるだろう、そしてデータを直感的に操作する間隔は失われてしまう。
ダイアログが表示されても集中していられるのは10秒までだ、それより長い遅延だと、終わるのを待つよりもユーザーは他のタスクを実行したいと思ってしまうだろう。
PJAXやTurboLinksといったような技術は不幸なことにこのセクションで記述された"あえて遅延させるような技術"を使う機会は失われてしまいます。クライアントサイドのコードはサーバーが起きている全てのラウンドトリップが終わるまで、ウェブページの中で最終的にどんな表示がされるのかは "知らない" と思ってください。
3. データ変更に反応しよう
tl;DR: サーバーのデータが変更された時、リクエストが無くてもクライアントはその変更を知る事ができるでしょう。これは手動でF5を押したり更新したりする事からユーザーを開放するためのパフォーマンス改善です。新しい変更というのは(再)接続管理や状態変更も含みます。
第三の原則はソースや1台以上のデータベースサーバーの中でデータが変更された時のUIの反応についての話です。
ユーザーがページを更新する、AJAXで操作するまで静的なままのHTMLのスナップショットを提供する事は廃れてきています。
UIは自分で勝手に更新されているべきでしょう。
データの要素の数が無制限に増加するようなサイトでは自分自身で更新する事は特に重要です。時計、電話、タブレット、ウェアラブルデバイスは自分自身で更新される事を元に設計されています。
FacebookにPCを通してデータが入力された時に入力とほぼ同時にFacebookはニュースフィードがあるかどうかを確認します。静的にデータを表示することは最適ではありませんでしたが、人々が一日一回自分のプロフィールを更新した場合には意味があるでしょう。
写真をアップロードし、アップロードしたら即座に友達からイイねしてもらったり、コメントを受け取る事ができる場所で生活しています。ユーザー同士がアプリケーションを同時に利用している事を知るためにリアルタイムフィードバックが必要になってきています。
マルチユーザーアプリケーションでしかリアルタイムフィードバックはメリットが薄いと推測するのは間違っているかもしれません。私がユーザーに反対してでもconcurrent data pointsについて話をしたいと思っている理由です。あなたのスマホで写真をラップトップにもシェアするという共通のシナリオで考えてみましょう。
ユーザーに見せる全てのデータをリアクティブとして考えるとわかりやすい。セッションやログイン状態の同期はこの原則を適用する例の一つになるでしょう。もしあなたのアプリケーションのユーザがたくさんのタブを同期的に開いてたとしたら、一つのアプリでログアウトしたら全てのタブに対してページを無効化するほうが良いでしょう。プライバシーとセキュリティを向上させる事につながります、特にたくさんのユーザーが同じデバイスにアクセスするようなシチュエーションで効果を発揮します。
一度、スクリーン上の情報が自動的に更新される事が期待されていました、これからは新しいニーズとして state reconciliation(状態の折り合い)を入れるか検討することが重要になってきています。
アトミックなデータ変更処理を受け付けた時、アプリケーションは適切に更新できるのかどうかを忘れて、勝手に更新するというのは簡単です。でももしもネットワークに未接続な状態で長い期間経過した後だったらどうなるでしょう。ラップトップを一回閉じて、何日か経ったあとで再度開いたというシナリオを想定してみましょう。そのときあなたのアプリケーションは何がどうなっているでしょうか?
時間内にバラバラの状態から折り合いをつける能力は私達の最初の原則にも当てはまります。もしあなたが初期ページロードにデータを送信する方を選ぶのであれば、オンラインになってからクライアントスクリプトがロードされるまでの時間を考慮しなくてはいけません。その時間は本質的に接続していない時間と同じものと見なす必要があります。
4. サーバーとのデータ交換をコントロールする
tl;DR:
サーバーとのデータ交換は今では微調整することができるようになってきています。エラーの発生を確認し、ユーザーの操作を再実行させ、バックグラウンドでデータを同期し、オフラインでキャッシュを維持しましょう。
WWWが考えられ始めた時、クライアントとサーバー間でデータを交換する方法はかなり制限されていました。
- リンクをクリックする事で新しいページを
GETし、レンダリングする POSTやGETをformから送信して新しいページをレンダリングする- 画像またはオブジェクトを非同期に
GETして埋め込み、レンダリングする
このモデルの単純さは魅力的であり、データがどうやって送信されて、受信されるのかを理解しやすく、かなり学習しやすいといえるでしょう。
最も大きな制限は第二の点(formからGETやPOSTでデータを取ってくる点)にありました。新しいページをロードせずにデータを送信する事はできませんでした。パフォーマンスに注目すると最善とはいえませんでした。しかもformからPOSTで送信した場合に戻るボタンを壊すことができてしまいます。
アプリケーションプラットフォームとしてのウェブはJavaScriptなしでは考えられません。AJAXはこういったユーザーが情報の送信する際のUXに関する障害を超えてきました。
今ではたくさんのAPIがあります。XMLHttpRequest, WebSocket, EventSourceといったAPIはデータの流れに対して、きめ細やかなコントロールを提供してくれます。ユーザーがフォームに入力したデータを送るという機能に加えてUXを改善するための機会をいくつも持っているわけです。
特に前の原則に適している機能は接続状態を表示する機能です。もしデータが自動的に更新される事を予測して準備するならユーザーに切断されたことや再接続中の状態を通知するべきでしょう。
切断を検知すれば、メモリやlocalStorageのような場所にデータを保存して後で送信するということができるようになります。これはJavaScriptのウェブアプリケーションがバックグラウンドで動作できるようにするServiceWorkerの導入を踏まえた上でとても重要なものになります。あなたのアプリケーションがオープンじゃなかったら、バックグラウンドでユーザーデータを同期しようとすることもできます。
データを送るときやユーザーの代わりにリトライする時はタイムアウトやエラーを考慮しましょう。接続が再確立したらデータを再送するように検討しましょう。永続的に失敗する場合、ユーザーに連絡しましょう。
明らかなエラーは注意深く扱われるべきです。例えば予期せず403エラーが発生している場合、ユーザーのセッションが無効になっている事を意味します。そういった場合、処理を継続させるためにログインスクリーンを見せることでユーザーにセッションが切れている事を理解させた方が良いでしょう。
ユーザーが不注意にデータフローを止めてしまわないか確認することも重要です。これは2つの状況下で発生する可能性があります。一つはブラウザやタブをうっかり閉じちゃうこと、これは閉じられる前に beforeunload ハンドラ関数で防ぐようにできます。
もう一つはページ遷移が起きてしまうことです。これは発生前にページ遷移を捉えることができます。例えばリンクがクリックされたら新しいページとしてロードさせるといった形です。新しいタブとして表示するだけじゃなく、自身のモーダルで表示させることも可能です。
5. historyを壊すべきじゃない、historyを拡張しよう
tl;DR: URLを管理するブラウザとhistoryがなければ、新たなチャレンジは生まれない。無限スクロール等の技術でhistoryを壊していないか確認しよう。高速なフィードバックのためのキャッシュを常にキープしよう。
フォーム送信やハイパーリンクのみのウェブアプリケーションの設計をするならブラウザの機能にある進む、戻るボタンを使うだけで終わるでしょう。
典型的な"無限ページネーションシナリオ"を例として考えてみましょう。JavaScriptでクリック/スクロールイベントを捕捉し、データやHTMLをリクエストし、それをページにインジェクションするという一連の動作を含めて実装するのが典型的な方法です。history.pushStateやreplaceStateを使うのはoptionalなステップですが、不幸なことにそんなに多くの情報をhistoryに入れることはできません。
これこそが私が"壊す"とうい言葉を使った理由です。ウェブが初期に提案したよりシンプルなモデルには、この将来像は描かれていませんでした。全ての状態遷移がURLの変更に依存することになるとは思われていなかったのです。
これは逆に言うと、historyを改善する新しい機会が生まれたとも言えます。私達開発者がJavaScriptでhistoryをコントロールできるようになったのです。
Daniel PipiusがFast Backと名づけた記事から引用すると:
"戻る"のは素早く行われるべきだ。ユーザーは"戻る"事によってデータが変更されるような事は期待していない。
これはブラウザの戻るボタンをアプリケーションレベルの普通のボタンとして考えるのと同じことです。これには2つめの原則 (ユーザー入力に迅速に対応しよう)と同じ原則が当てはまります。前のページをどうやってキャッシュするかを決め、即座にレンダリングするのがキーになります。原則3のデータ変更に反応しようにも当てはまります。ユーザーの新しいデータ変更があったら通知し、そのページに反映する必要があります。
開発者がcache behaviorを制御しない、いくつかのケースが存在します。例えば、ページをレンダリングした後、3rdパーティ製のウェブサイトに行き、ユーザーが戻るボタンをクリックしたとします。アプリケーションはサーバーにあるHTMLを再度レンダリングし、クライアント上でHTMLを変更します。この時、微妙で分かりにくいバグが入ってしまうリスクが有ります:
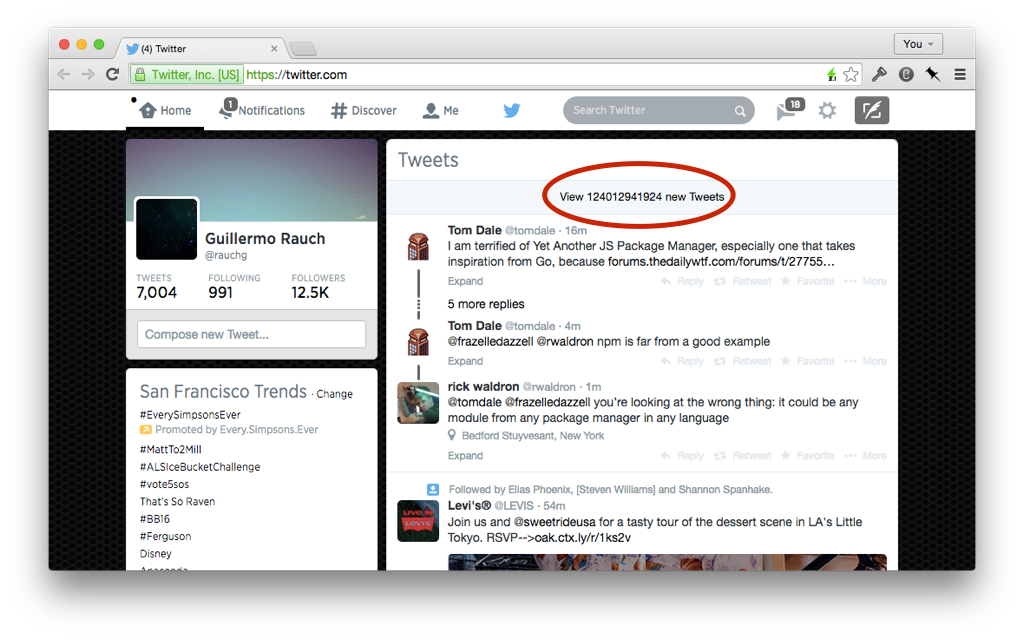
他にもナビゲーションを壊してしまう方法があります。スクロールのメモリを無視するとナビゲーションを壊すことができます。JSに依存しないページや手動でhistory管理するページはほとんどがこの問題にぶつかることはありません。しかし動的なページは常にこの危険があります。私は2つのポピュラーなJavaScript-drivenのニュースフィードを試してみました。TwitterとFacebookです。両方共scrolling amnesia (スクロール位置の喪失)が発生しました。
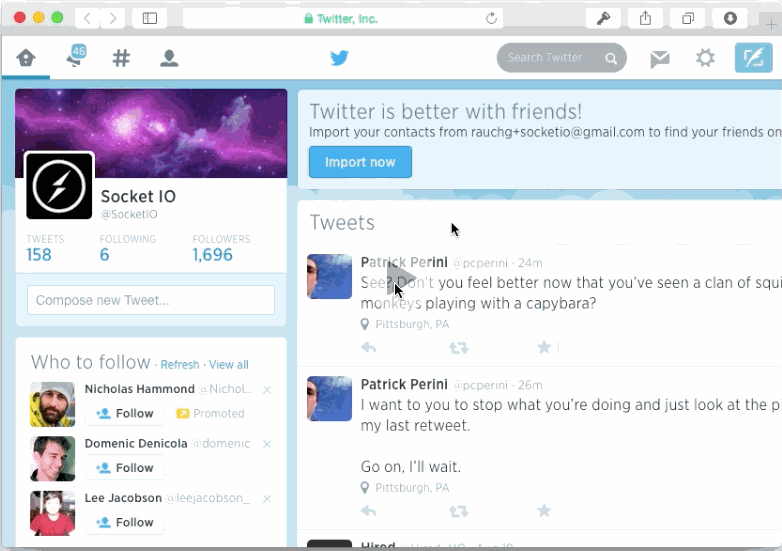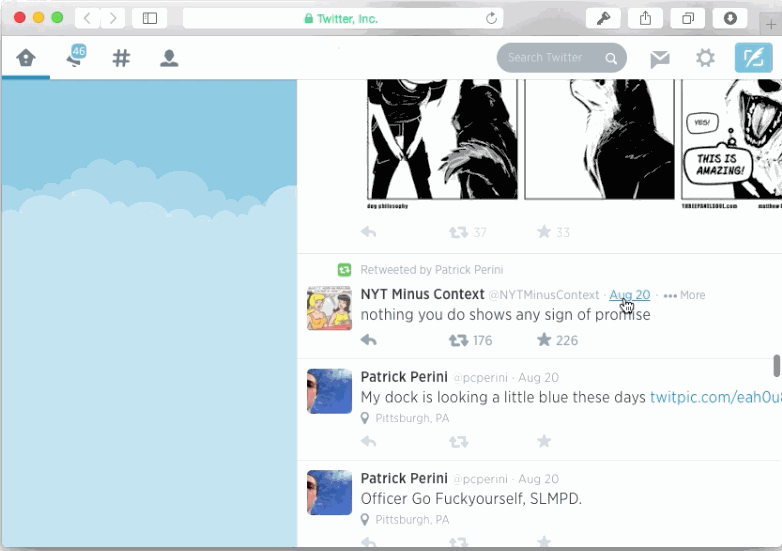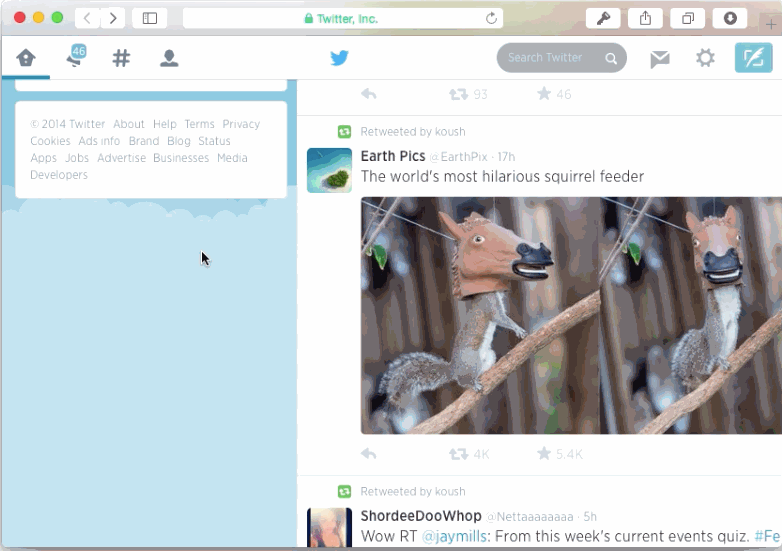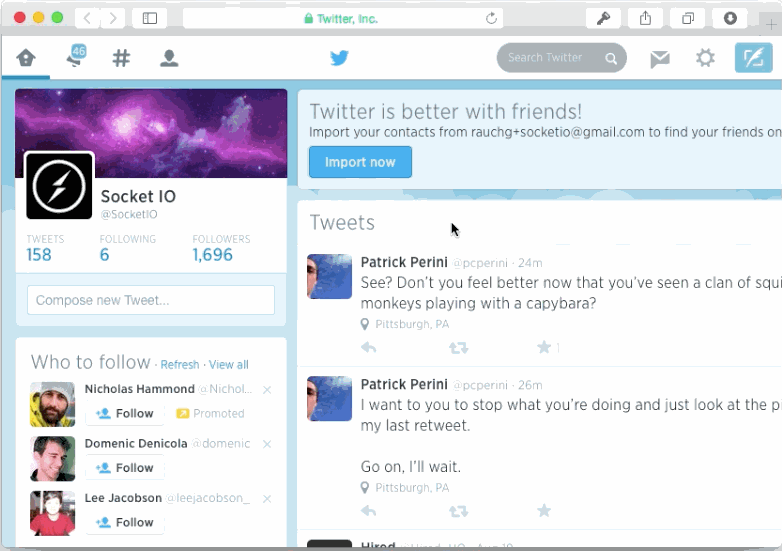
最終的に、状態変更に気づくことがhistoryをナビゲートする際に適しています。コメントサブツリーの表示をtoggleする例を考えてみましょう。
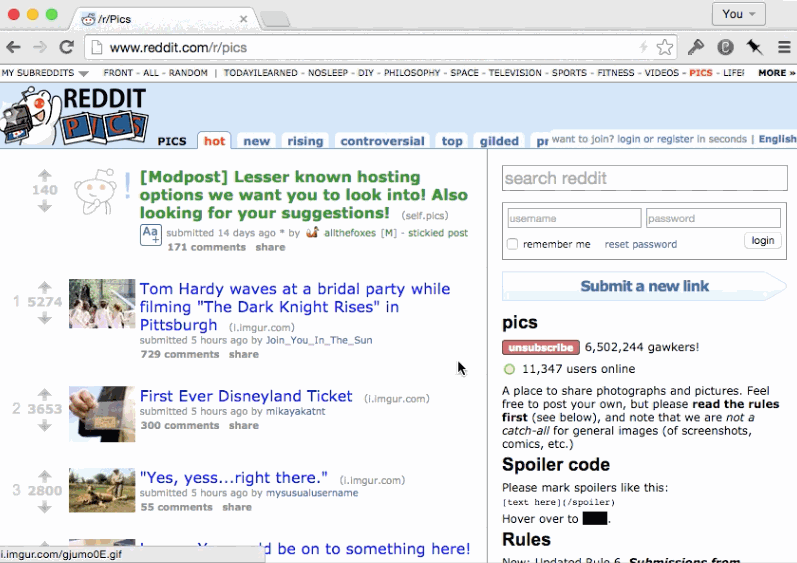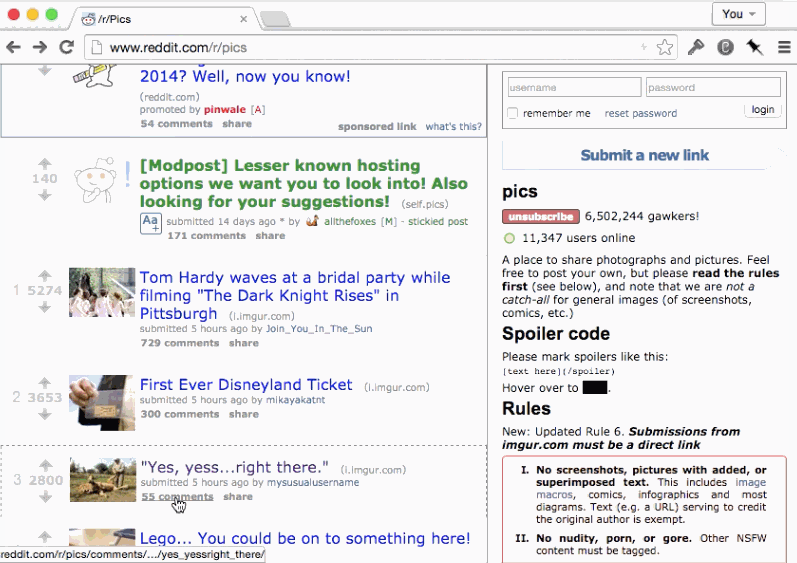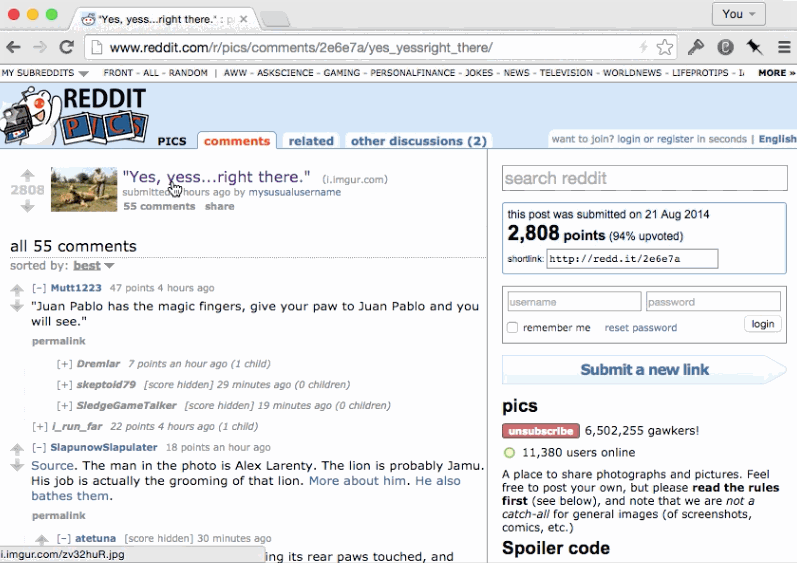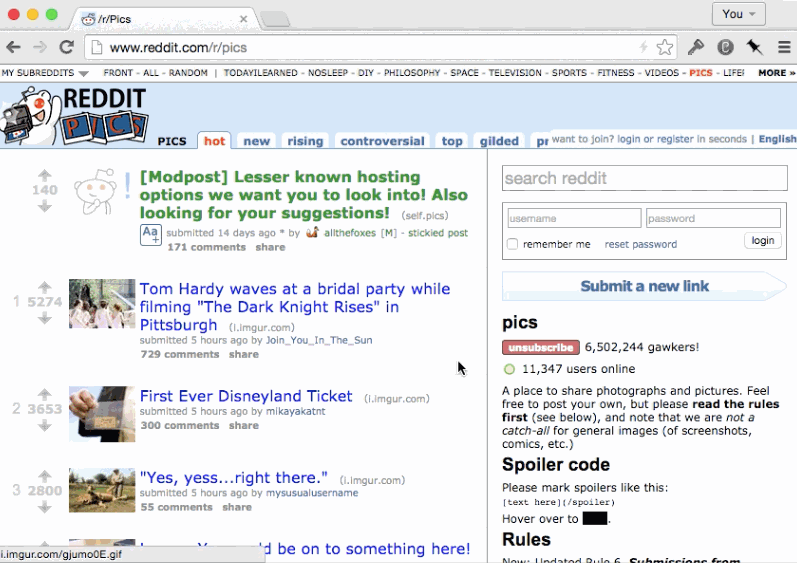
もしそのページがアプリケーション内のリンクにしたがって再描画されたのであれば、ユーザーは全てのコメントが閉じたまま描画される事を期待するでしょう。状態はvolatileでありかつ、historyスタック内でのエントリと関連付けられるようにしましょう。
6. コードの更新をPushしよう
tl;DR: コードをPushしないでデータだけPushするのは不十分だ。もしデータが自動的に更新されるなら、コードもそうなるべきだろう。APIのエラーを回避してパフォーマンスも改善される。再描画しやすく副作用が少ないステートレスなDOMを使おう。
アプリケーションがコードの変更に反応することは重要です。
最初に、表面に見えてしまうようなエラーは限りなく減らして、信頼性を向上させるべきです。もしもバックエンドのAPIに対して互換性のない変更がある場合、クライアントのコードは更新されなければならないでしょう。さもなければ新しいデータが理解できない可能性があり、互換性のないフォーマットのデータが送られる可能性があります。
コードの変更をPushするもう一つの重要な利点は第三の原則(データの変更に反応しよう)の実装をする時に必要になるという事です。もしUIが自分で更新されるんだとしたら、ユーザーが自分でページ更新を行う理由は殆どありません。
traditionalなウェブサイトのことを思い出してください、ページの更新には2つの意味があります、データの更新とコードの更新です。データをpushする仕組みを準備するだけでコードをpushする仕組みがないのは不十分です、特に単一タブ(単一セッション)は長い期間開かれていることが多いので、コードのpushが必要になります。
サーバーがpushするチャンネルが決まった場所にあるなら、新しいコードが利用可能になった時にクライアントにコードが変わったことを発信させることができます。そういう仕組が存在し無いなら、HTTPリクエストにクライアントコードのversion番号が追加されることになるでしょう。サーバーはそのバージョン番号を最新のバージョンと比較し、リクエストを処理するかどうかを選択し、時にはクライアントに忠告します。
この後、ウェブアプリケーションが適切だと判断したら、ユーザーの代わりにページをリフレッシュするようにします。例えば、ページが見えないとかフォームに何も入力できないという事態にならないようにします。
ホットコードリロードするというより優れたアプローチがあります。これは全ページのリフレッシュをする必要がありません。その代わり、実行中のコードをスワップさせてモジュールをロードし、再実行させるという機能が必要になります。
多くのコードが存在している状況では、明らかにホットコードリロードは難しくなるでしょう。アーキテクチャの種類ごとに議論する余地があります。振る舞い(code)から綺麗にデータ(状態)が切り離されているアーキテクチャである必要があります。そのように分離されたアーキテクチャはパッチを沢山当てた時(メンテナンスする時)に効果的になるでしょう。
アプリケーション内でのモジュールの例を考えてみましょう。そのアプリケーションはsocket.ioのようなイベントでやりとりする口が用意されているとします。イベントが受信された時、コンポーネントの新しい状態が導入され、DOMにレンダリングされるでしょう。その後、前の状態から新しい状態にDOMがマークアップされ異なるDOMが生成されます。これにより、コンポーネントの振る舞いを変更します。
ベースとなるモジュールごとにコードを更新することができるのが理想的なシナリオと言えるでしょう。もしコンポーネントのコードが変更され、更新されるようなタイミングで、例えばsocket接続から再起動するような事になると、意味がありません。
しかし、そうなると次のチェレンジとして、やっかいな副作用なしでモジュールが再評価されるようにできるようにしなければいけません。Reactによって提案されているようなアーキテクチャはこのチャレンジが特にやりやすくなるでしょう。もしコンポーネントのコードが更新されたら、ロジックは再実行され、DOMが効率的に更新されるようになるでしょう。Dan Abramovによるコンセプトの追求はここで見ることができます。
本質的には、"あるDOMにだけ"レンダリングする、もしくは描画するというアイデアはホットコードリロードをかなりやりやすくしてくれます。もしDOM内で状態が維持されていたら、もしくはアプリケーションによって手動でセットされたイベントリスナーがあったら、コードを更新することはより複雑なタスクになるでしょう。
7. 振る舞いを予測しよう
tl;DR: レイテンシーの壁を超えよう。
リッチなJavaScriptアプリケーションはユーザー入力を予測するという仕組みを持っています。
こういうリッチなアプリケーションはユーザーの操作が成立するまえに、前もってサーバーからデータをリクエストするというアイデアを共通して持っています。ハイパーリンクの上にマウスがホバーしたらデータをフェッチし、クリックされた時には既にデータがあるという状態はわかり易い例といえるでしょう。
応用例としては、マウスの動きをモニタし、その軌跡を分析させ、ボタンのようなクリッカブルな要素に対して"衝突"判定させる事です。jQueryの例を見てみましょう:

まとめ
ウェブは情報の送受信のための最も多彩なメディアの一つとして残り続けるでしょう。自身のページにより多くのダイナミズムを追加し続けていくことによって、新しいものを取り入れていく一方で、その歴史的につづいているWebの利点を保ち続けなければなりません。
ハイパーリンクによって相互接続されているページはどんなタイプのアプリケーションに対しても偉大な建造物です。ユーザーが操作するコード、スタイル、マークアップのロードは革新的になっています。この進化はインタラクティブ性を犠牲にすること無く、パフォーマンスを向上させるでしょう。
JavaScriptには最も広く、そして最も自由な既存のプラットフォームのためのUXの可能性を最大限に広げることでしょう。新しく、ユニークなチャンスは至るところで採用されているJavaScriptによって有効になっていくでしょう。
ES6+カジュアルトークを開催しました #es6_casual
ES6+カジュアルトークを開催しました。
Ustreamはこちらです。
Ustream.tv: ユーザー dena_tech: DeNA Technology Seminar #ES6+カジュアルトーク, Recorded on 2014/10/29. コンピュータ
僕はES6を追い始めたのが遅くて、ちゃんと追うようになったらもっと前に追っている人がたくさんいたので、その人達を呼んでカジュアルトークをしつつ、ガチで学べる会を開催しました。
全体的に発表レベル高くて濃い話が聞けたと思っています。
TL;DR
- ちょっとES6使ってみよっかなーな人はrunstantがオススメです。
- Node.jsの次のバージョンではarrow_functionがharmony付きで使えるようになります。Symbol, for-of, Collections, Object.observe, Promiseがデフォルトで使えるようになります。
- ES6からは不変なオブジェクトを作ることができます。関数型プログラミング入門にもなると思います。
- ただし、今でも既にprototype拡張を使ってメソッド拡張している人達はES6になったらぶっ壊れることもあるから気をつけて。
- Closure CompilerでもES6が書けるようになるよ。今後のAltJSには型が必須だよ。
- ES7からはMonolithic Releaseじゃなくて機能単位のリリースになるよ、今はES7に向けて型とかも提案されてるよ。
runstant 始めるEcmaScript6 入門 by @phi_jp
@phi_jpが作っているrunstantっていうエディタを使ってES6のハンズオンをする会。
オープニングに相応しい話をしてもらいつつ、ES6をとりあえず使ってみるっていう上では非常に面白い話だった。
ちなみにrunstantっていうツールは非常に良く出来ているのでオススメです。
Node.js v0.12で使えるようになるES6+αの機能 by @yosuke_furukawa
僕の発表。ES6の機能のうち、次のNode.jsで使えるようになるものをまとめた感じ。
簡単にいえば、v0.12からはアロー関数は使えるようになるが、harmonyオプションが必要です。その代わり、Symbol, for-of, Collections, Promise, Object.observeがデフォルトで使えるようになります。
今のところまだなのは、class, generator, block scopeとかですね。
Ecma script6による関数型プログラミング by @TanUkkii
ES6で関数型プログラミングするアプローチについての話。副作用を排すために何をES6として使ったほうがいいか、という切り口で斬新だった。
再代入できない変数としてconstを使う話と、分割再代入で代入処理自体を少なくする話、末尾最適化で再帰呼び出しを高速化する話と、最終的にProxyオブジェクトを使うことで不変な値を作るっていうアプローチは非常に面白かった。
別件だけど、jser.infoの200回記念イベントではObjectの変更を禁止するObject.freeze, seal系のメソッドはproductionでは使わないって言ってて、こういう不変な値を作るようなアプローチと性能をケアするようなアプローチの良い塩梅はどの辺なのか知りたいなと思った。
Introducing break the Web by @Constellation
資料なし
ES6がwebをぶっ壊してしまう可能性について言及した話。
詳しくはここ読むといいけど、with構文を使うと簡単に壊れそう。
あと、実際に壊れてしまった話のケーススタディとして、MooToolsの話、enumerableだったメソッドがES6からnon-enumerableになってしまった結果、for-inの中で登場しなくなり、結果としてメソッドが無くなってしまった。これを使っているプロダクト全体が壊れた。
まとめとして:
- 短縮化されたコードを書くな、inではなく、hasOwnProperty使いましょう
- Object.prototypeとか将来的に拡張される可能性があるのでそういうの考えよう
- with使うな
という示唆に富んだ話でめっちゃ面白かった。
Closure CompilerのES6対応あるいはES6時代のAltJS生存戦略 by @teppeis
Traceur CompilerもES6のtranspilerだけど、同じくGoogle製のClosure CompilerもES6からcurrent JavaScriptに変換できるようにしていっているという話で、未来があって面白かった。TCはちょっと大きめのruntime scriptを読み込む必要があるんだけど、CCの場合はruntime scriptが小さいし、最終的にconcatされると小さくなるっていう話は良かったと思う。今だとruntime script不要な6to5が出てきてたりするので、transpiler戦国時代の今にClosure Compilerが切り込むのは良いと思った。
あと、これからのES6以降のAltJSではやっぱり型が重要になってくるし、ES7にOptional Typeを入れるためにもAtScriptとかTypeScriptの動きが重要になる。とりあえずFacebook Flowマダー!!!!
明日には使えなくなるES7トーク by @azu_re
ES6よりも未来、ES7でどうなっていくかっていう話。これは今のプログラミング言語全体に言えることだと思うんだけど、バージョンアップするっていうときに機能セットをいくつか作成して、その機能セットが全て出来上がってからリリースっていうサイクルになっていると思う。これの一番の問題はバージョンリリースが遅れることだ。こういう機能セット単位でできあがってからリリースしていくことをmonolithic releaseと呼ばれていて、変化が激しいWebの業界では変化が遅い事は問題になりやすい。
それよりも機能単位で検討していき、ひとつの機能単位で標準化していったほうが全体を決めるよりも早い。こういうスタイルでES7は標準化を検討していく、とTC39では発表があって、これがこれまでとの一番の違いだと思う。
ちなみにこの機能単位でリリースすることを feature-based modelって言うらしい。
そんな中で今、ES7では、async構文やTypesの提案、末尾カンマといった提案がされているという話だった。
特に皆がお待ちかねの型に関しては提案段階だし明日にはどうなるかわからない、という話だった。
先は長いかもしれないけど、全体的に型が必要という提案がされてきているようなので、待っていきましょう。
まとめ
ES6+カジュアルトークですが、ものすごく濃い話がちゃんと聞けてよかったなと思います。
こういう上級者というか知っている人がちゃんと集まって濃い話する勉強会は非常に有用ですね。
またES6に限らず何か一個のトピック掘り下げて勉強会開催したいと思います!
traceur-compiler 入門
最近ちょっとはまってるtraceur-compilerについて紹介していきます。
前書き
今回、書いてたら非常に長くなってしまって、ちょっとした薄い本の記事くらいの文量があります。
その代わり、公式ドキュメント + コードの中を読みこんで書いているので、今のところ多分日本では一番詳しい記事かと思います。
すごく長いので章分けしました。興味が有るところだけ読み飛ばしてもらってもいいかと思います。
第一章 traceur-compiler概要
traceur-compilerとは
Googleが作っている EcmaScript6 形式で書かれた JavaScript を EcmaScript5 の形式に変換してくれるツールです。"トレーサーコンパイラー"と読みます。
最初にその名前を聞いたのは 2011年の NodeConf の発表でした。3年の後に多くのES6の機能をサポートし、次のAngularJSではES6 + traceur compilerで書かれると発表されるなど、大きなプロダクトで採用されようとしています。
ES6の文法や新機能をフルサポートしたブラウザは現時点では存在しませんが、traceur-compilerがES5の形式に変換してくれることで対応していないブラウザでも実行できるようになるという嬉しい機能を持っています。
また、traceur-compilerの機能の一つですが、traceur-compilerのランタイムエンジンを使うことでアクセス時にES5に変換してくれるという機能をもっているため、直接ES6で書いて、ブラウザに評価させることができます。
traceur-compilerで何が嬉しいのか
ES6は仕様fixが来年6月に延長されたとはいえ、盛り上がりを見せています。
Chromeの開発ビルド(Canary)やFireFoxの開発版(Aurora)にも多くのES6機能追従がされてますし、一部の機能は既に今のブラウザでも扱えるようになっています。
またJavaScriptには他の言語には必ずあるような一般的な機能が欠落している事も多く、それをカバーするためにUnderscoreといったライブラリやCoffeeScript, TypeScript, JSXといったaltJSが台頭しています。
ES6に対応したJavaScirptを使うことで、ライブラリの機能が不要になり、依存ライブラリを減らすことができたり、altJSに頼らなくても豊富な言語機能が扱える可能性が広がります。
また数年後にはES6が広まっていることを考えるとその時までにES6の新文法、新機能に慣れておいたほうがスムーズな移行が期待できます。
また、最終的にはtraceur-compilerはES6が広まることで捨てることができる、という点が他のaltJSやライブラリ群と比較して最も優れていて嬉しい点だと思います。
Getting Started
何はともあれ始めてみましょう。traceur を使ってES6を活用するにはオンラインでES6を直接実行する場合と、事前にオフラインでES6からES5に変換してから構文を実行させる2通りの方法があります。
オンラインでES6を実行する
とりあえずES6のコードを動かすだけなら以下のようにtraceur.jsとbootstrap.jsを読み込むだけで実現可能です。
以下の例では、ES6にあるクラス構文とblocking scope(let)を扱った例を紹介します。
<!DOCTYPE html> <html> <head> <title>Hello World!</title> </head> <body> <h1 id="message"></h1> <!-- traceurのランタイムエンジンを読み込む --> <script src="https://google.github.io/traceur-compiler/bin/traceur.js"></script> <script src="https://google.github.io/traceur-compiler/src/bootstrap.js"></script> <!-- letはまだtraceurとしてはexperimentalな機能なのでexperimentalフラグを立てる --> <script> traceur.options.experimental = true; </script> <script type="module"> // Greeterというモジュールを作り、読み込むとh1タグにHello Worldと出るようにする // classが定義できる class Greeter { // constructorメソッドを作るとnewの時に読み込まれる constructor(message) { this.message = message; } // greetメソッド greet() { // letという新しい変数定義 // letを使うとblocking scopeといってこのblock内でしか有効じゃない let element = document.querySelector('#message'); element.innerHTML = this.message; } } let greeter = new Greeter('Hello, world!'); greeter.greet(); </script> </body> </html>
これだけで実行すると以下のような感じになります*1。

さて、オンラインで実行するのはデモには良いのですが、毎回アクセスする度にES6からES5への変換が内部で走るのでそのオーバーヘッドがかかることになり、非効率的です。効率的に実行するならトランスパイル済みのものを配布する方がよいでしょう。
コマンドからES5にトランスパイルする
というわけで事前にトランスパイルを行いましょう。
事前にトランスパイルするならtraceurコマンドが必要になります。
$ npm install traceur -g
さっきの例とはちょっと違ってES6のgenerator関数を使った例でfibonacci数列を出してみましょう。
// fibonacci関数をgenerator関数を使って書く // generator関数はfunction*で定義する function* fibonacci(){ // ES6の場合変数定義の基本はletにした方が良くなるはず... let fn1 = 1; let fn2 = 1; for (;;){ let current = fn2; fn2 = fn1; fn1 = fn1 + current; // yieldで足しあわせた数を返す yield current; } } // for-ofによる繰り返し、generator関数はiterableなオブジェクトを返すので、 // iterableなオブジェクトを繰り返すには for-of文を使う for (let seq of fibonacci()) { // 1000までいったらbreak, つまり1000までの数しかfibonacci数列の表示を行わない if (seq > 1000) { break; } // #fibタグ以下に書く let element = document.querySelector('#fib'); let p = document.createElement("p"); p.innerHTML = seq; element.appendChild(p); }
これを適当に fib.js とかにして保存したら、以下の方法でtraceurコマンドを実行してください。
$ traceur --out [出力先] --script [入力元]
# experimentalオプションをオンにする $ traceur --experimental --out dist/fib.js --script fib.js
こうしておくと、dist/fib.jsにトランスパイルした結果を出力してくれます。
ただ、トランスパイルしたとしてもtraceurの実行時にtraceurのruntimeスクリプト(traceur-runtime.js)は必要になります。
なので、htmlは以下のようになります。
<!DOCTYPE html> <html> <body> <div id="fib"></div> <!-- traceurのruntimeスクリプトが必要 --> <script src="https://google.github.io/traceur-compiler/bin/traceur-runtime.js"></script> <script src="dist/fib.js"></script> </body> </html>

generator/yield/for-ofを使ったES6の構文でフィボナッチ数列が出ていることが分かるかと思います。
このtraceurを使うことでgeneratorやyieldやlet、for-ofといった構文でもES5の構文にトランスパイルされます。
トランスパイル後のファイルがどうなってるかに関しては次章以降の話にします。
traceur コマンドで逐次実行する
トランスパイルするだけじゃなくて、traceurコマンドを実行することでその場でスクリプトを評価することができます。
$ traceur [実行したいスクリプトへのパス]
$ traceur es6.js
第一章まとめ
- traceur-compilerの概要説明
- Getting Started
- REPL等の便利ツール
第二章 ES6言語仕様概要
traceurが提供する言語機能一覧
traceurがサポートしているES6の機能一覧を紹介していきます。実はtraceurはES6だけじゃなくてまだproposalでしかないような言語の機能も提供しています。この部分を読んでおくとtraceurが今提供しているものが分かるので、traceurからES6を学ぶ人は抑えておくとよいでしょう。
本章の説明は長いので、ES6の内容を既に知っている人は読み飛ばして第三章の話を読んだほうが良いです。
Array Comprehension
いわゆるArray内包表記というやつですね。配列の中でforを使って演算させる事が可能です。
具体的には以下のように書くことが可能です。
var array = [for (x of [0, 1, 2]) for (y of [0, 1, 2]) x + '' + y]; console.log(array); // '00', '01', '02', '10', '11', '12', '20', '21', '22'
これがあると配列の初期化時に柔軟にコードを実行できるようになります。
Arrow Function
アロー関数、CoffeeScriptとかだとよく見ますね。
// (x) => {} で関数定義になる // 今までだと var square = function(x) { return x * x; }; var square = (x) => { return x * x; }; console.log(square(4)); //16 // 引数が一つならカッコを省略できるし、returnの一行しかbodyがないならreturnも省略可能 var square2 = x => x * x; console.log(square2(4)); //16 // 引数を受け取りvalueプロパティを持つオブジェクトに格納してreturnする関数 var objectify = x => ({ value: x }); console.log(objectify(4)); //{ value:4 }
アロー関数は先日のjs.nextでも話題になってましたね。chromeのcanaryでの実装は始まったようですが、stableで有効になるのはもう少し先でしょう。
Classes
第一章の例でも登場したクラス。
クラスと継承がサポートされたことで以下のように書くことが可能です。
// Characterクラス class Character { constructor(x, y) { this.x = x; this.y = y; this.health_ = 100; } attack(character) { character.health_ -= 10; } } // 当然継承もある。 // Monsterクラスに継承 class Monster extends Character { constructor(x, y, name) { super(x, y); this.name = name; } // メソッド書くときはこう書く attack(character) { // 親クラスのメソッド呼ぶときはこう super.attack(character); // super(character)でも同じ意味になる } // get prefixを付けられる get isAlive() { return this.health_ > 0; } get health() { return this.health_; } // set prefixを付けられる set health(value) { if (value < 0) throw new Error('Health must be non-negative.'); this.health_ = value; } } var myMonster = new Monster(5,1, 'arrrg'); var yourMonster = new Monster(5,1, 'nyan'); // get prefixをつけるとプロパティアクセスのようにメソッドを扱える console.log(myMonster.health); // 100 console.log(myMonster.isAlive); // true // set prefixでも同様。 myMonster.health = 1; console.log(myMonster.health); // 1 console.log(myMonster.isAlive); // true myMonster.attack(yourMonster); console.log(yourMonster.health); //90
Computed Property Names
プロパティのキーに演算ができるようになりました。
var x = 0; var obj = { [x] : 'hello', [x+1] : 'world' }; console.log(obj); // {0: 'hello', 1:'world'}
Default Parameter
引数にデフォルトのパラメータを取ることができるようになりました。
function f(list, indexA = 0, indexB = list.length) { return [list, indexA, indexB]; } console.log(f([1,2,3]); // [1,2,3], 0, 3 console.log(f([1,2,3],1); // [1,2,3], 1, 3 console.log(f([1,2,3],1,2); // [1,2,3], 1, 2
Destructuring Assignment
デストラクチャリング、和訳すると分配束縛と呼ばれる機能です。Clojureにある機能ですね。
これを利用すると配列やオブジェクトで設定した値を取り出しやすくなります。
一番良く使うのは値をswapさせる時かと思います。
具体的には以下のとおり。
var hoge = 123; var fuga =456; // 値をswapする var [fuga, hoge] = [hoge, fuga]; console.log(hoge); // 456 console.log(fuga); // 123 var [a, [b], [c], d] = ['hello', [', ', 'junk'], ['world']]; console.log(a + b + c); //hello, world (aに"hello", bに",", cに"world"が入ってる ) var pt = {x: 123, y: 444}; var {x, y} = pt; console.log(x, y); // 123 444
Iterators and For Of
Iterableなオブジェクトを作れるようになり、それをiterateさせるためにFor-Of構文を使うと綺麗に書けます。
var res = []; for (var element of [1, 2, 3]) { res.push(element * element); } console.log(res); // [1, 4, 9]
Iterableなオブジェクトを作るにはSymbol.Iteratorを使います。toStringのiterate版、いわゆるtoIterateみたいなものだと思ってください。
// 1000までの値を返すfibonacciを作る var fibonacci = { // Symbol.iteratorを持つメソッドを持つオブジェクトにする [Symbol.iterator]() { let pre = 0, cur = 1; // iteratorオブジェクトは nextメソッドを持つオブジェクトを返す return { next() { // nextの中では返す値(value)と次で終わりかどうかを示すプロパティ(done)を返す [pre, cur] = [cur, pre + cur]; if (pre < 1000) return { done: false, value: pre }; return { done: true }; } } } } for (var n of fibonacci) { console.log(n); }
Generator Comprehension
Array Comprehensionの時にも出てきたけど、Generator関数もfor ofで値を加工して新しい配列を作ったりすることが可能。
var list = [1, 2, 3, 4]; // 実は (function*(){ for (var x of list) yield x })();と同じ var res = (for (x of list) x); var acc = ''; for (var x of res) { acc += x; } console.log(acc); // "1234"
Generators
Iterableなオブジェクトを作るときには最も効力を発揮するgenerators、さっきのfibonacciの例で使うとこうなります。
// 1000までの値を返すfibonacciを作る function* fibonacci(){ let pre = 0, cur = 1; while (pre < 1000) { // ここでdestructuringで値をswapさせる。 [pre, cur] = [cur, pre + cur]; // yieldで値を返す yield pre; } } for (let n of fibonacci()) { console.log(n); }
Symbol.Iteratorを使った例と比較するとgeneratorsがどれだけ使いやすいか分かるかと。
Modules
これまでモジュールの参照解決にはrequire.js使ったりBrowserify使ったりしてたんですが、ES6のロード機能によってこれらが言語仕様レベルで解決されます。
// Profile.js // exportで外から見えるようにすることが可能 export var firstName = 'David'; export var lastName = 'Belle'; export var year = 1973;
//ProfileView.js import {firstName, lastName, year} from './Profile'; function print() { console.log(firstName + ' ' + lastName + ' ' + year); //David Belle 1973 } print();
HTMLで読み込みたい場合はmodule属性にして読み込みます。
<script type="module" src="ProfileView.js"></script>
Numeric Literals
10進数や16進数の数字だけじゃなく、2進数とか8進数とかの数字を直接書けるようになります。
var binary = [ 0b0, 0b1, 0b11 ]; console.log(binary); //[0, 1, 3] var octal = [ 0o0, 0o1, 0o10, 0o77 ]; console.log(octal); // [0, 1, 8, 63]
Property Method Assignment
プロパティメソッドとして簡略的にメソッドが書けるように成りました。
var object = { value: 42, //直接toString()って書ける // 今までだと toString: function() {} って書く必要がある toString() { return this.value; } }; console.log(object); //{ value: 42, toString: [Function] }
Object Initializer Shorthand
オブジェクトの初期化を短く書けるようになります。
function getPoint() { var x = 1; var y = 10; // ここでオブジェクトにしている。 // 今までだと {x: x, y: y} って書く必要がある return {x, y}; } // {x: 1, y: 10} console.log(getPoint());
Rest Parameters & Spread
可変長パラメータによって以下のように関数を表現すること(Rest Parameters)も、配列を可変長パラメータに展開して渡す事(Spread)も可能です。
// ...itemsで可変長パラメータ function push(array, ...items) { // それをarrayにpush // 今までだと items.forEach(function(item) {array.push(item);});って書く必要がある array.push(...items); } var list = [1, 2, 3]; //list変数に数字をpush push(list, 4, 5, 6); console.log(list); //[1, 2, 3, 4, 5, 6] function add(x, y) { return x + y; } var numbers = [4, 38]; //配列を数字に展開している console.log(add(...numbers)); // 42 var a = [1]; var b = [2, 3, 4]; var c = [6, 7]; // こんな書き方も。配列を結合するのに便利 var d = [0, ...a, ...b, 5, ...c]; console.log(d); // [0, 1, 2, 3, 4, 5, 6, 7];
Template Literals
文字列内で変数展開、式展開することが可能です
var name = 'world'; //ここで変数展開する、これによってworldっていう文字列を埋め込んでいる var greeting = `hello ${name}`; console.log(greeting); // hello world var hoge = 1; var fuga = 2; // 式を評価することも可能。 var moga = `${hoge + fuga}`; console.log(moga); // 3 // 複数行の折り返しも書ける var multi = ` (-_-) | | | | `; /* (-_-) | | | | */ console.log(multi);
Promises
非同期処理の成功時と失敗時の切り分けができるようになる機能です。
function timeout(ms) { // Promiseのresolve関数を受け取る return new Promise((onFulfilled, onRejected) => { // 50%の確率でonFulfilled, onRejectedが呼ばれる setTimeout(() => Math.random() > 0.5 ? onFulfilled() : onRejected(), ms); }); } function log() { console.log('done'); } function error() { console.log('error'); } // onFulfilledが出たらdone、onRejectedだったらerrorと表示する timeout(100).then(log).catch(error)
Block Scoped Binding (Experimental)
let, constといったblockスコープです。JavaScriptの場合、スコープを表現するのにfunctionで囲む必要がありましたが、letを使うことで、functionだけではなくブレースやブラケットで囲まれた領域がスコープに成ります。
ただこれはExperimentalとされていて、通常はtraceurでコンパイルできません。experimentalフラグを立てる必要があります。
// block.js { var a = 10; let b = 20; const tmp = a; a = b; b = tmp; } // a = 20、aはvarで宣言しているのでブロックスコープの外からも参照可能。 console.log(a); // letで定義したbはブロックスコープの外からは解決できない、b is not defined console.log(b); // constもスコープの中でのみ有効、tmp is not defined console.log(tmp);
トランスパイルする際は以下のようにする
$ traceur --experimental block.js
ちなみにletとかconstに限らない話ですが、traceurにはfree-variable-checkerという未定義の変数をチェックする機能があります。これを使うとトランスパイル中に未定義の変数に対して警告を出すことが可能です。
$ traceur --experimental --free-variable-checker --out block_compiled.js --script block.js [Error: b is not defined]
Symbol (Experimental)
Symbolを使うことでJavaScriptにprivateな値を持たせることが可能です。
Symbolもexperimentalオプションが必要になります。
var object = {}; { // このブロックでしか有効じゃない値でSymbolを作る var visible = Symbol(); let invisible = Symbol(); // object自身は外から見えるが、symbolの値は同じsymbolでしか // 取れないためpropertyのkeyをblockスコープにしてからsymbolを使うと外から見えなくなる object[visible] = 42; object[invisible] = 84; // 42 console.log(object[visible]); // 84 scopeの中では有効 console.log(object[invisible]); } // 42 visibleな値は取れる console.log(object[visible]); // {} invisbleな値が見えてない console.log(object);
Traceur が提供する言語機能のまとめ
ここまでがES6からES5にトランスパイル可能な機能一覧です。
これ以外にもES6で提案されている仕様はあるんですが、ブラウザの機能に深く食い込んでてpolyfillで解決できないどうしようもない機能(WeakMapとか)はおそらくTraceurでは実装できないでしょう。またProxy APIはFireFoxでは実装が進んでいるんですが、現時点ではTraceurではトランスパイルできません。
traceurが提供するES6の機能と各ブラウザベンダが提供する機能の比較一覧は以下の表を見ると分かりやすいです。
ES6以外のTraceur Compilerが提供する機能
実はES6からさらに進んだ機能、ES7で提案されている機能もTraceur Compilerでは扱うことができます。
Async Functions (Experimental)
async/awaitと呼ばれるC#にある機能ですね。
async修飾子をfunctionにつけることでawait句という特別な構文が使えるようになります。
先ほどのPromiseの例をAsync Functionで書くとこうなります。
function timeout(ms) { // Promiseのresolve関数を受け取る return new Promise((onFulfilled, onRejected) => { // 50%の確率でonFulfilled, onRejectedが呼ばれる setTimeout(() => Math.random() > 0.5 ? onFulfilled() : onRejected(), ms); }); } function log() { console.log('done'); } function error() { console.log('error'); } // Promiseをwrapしてthenの部分とcatchの部分を分割することができる async function asyncLog() { await timeout(500); log(); } async function asyncLogger() { await asyncLog().catch(error); done(); } asyncLogger();
Promoseだけじゃなく、Generatorsも対象としているようで、言語仕様レベルで非同期処理を同期処理っぽく書くためのフローを提供しようとする枠組みですね。Node.jsにはcoというライブラリがありますが、それと非常によく似ています。
まだES7のproposalというステータスなので、今後が楽しみではあります。もちろんexperimentalです。
Types (experimental)
型の情報を関数の引数に明示できるという機能です。
JavaScriptは動的型付け言語なので、型の情報を明示出来るとそれだけでも割りと夢が広がります。
といってもトランスパイル時に警告するとかそういう機能はtraceurは提供していません。
Typesを書くことで実行時に関数内で引数チェックしてくれる仕組みが提供されています。
これにより、関数呼び出しの際の引数の型チェックを実装しなくても言語側で実装してくれるという嬉しい機能ですね。ただ重ねて言いますが、ランタイム時のチェックしかしてくれません。
もしもTypesが標準化されたらESLintとかそういうLintツール上でチェックしてくれると嬉しいですね。
class TypeTest { // 型情報として 第一引数がstring, 第二引数が numberであることを書く。 constructor(x : string, y : number) { this.x = x; this.y = y; } } // コンストラクタを呼び出した時に敢えてstringとnumberの順序を逆にする。 // この時にランタイムエラーで実行に失敗し、警告が出る。 new TypeTest(1, "hoge");
このコードを実行するには多少前準備が必要です。全然手順が書かれてないのでドキュメントにない機能なんですが、使えることには使えます。
まず、assert関数を使えるようにするためにここからassertのファイルをcloneしてください。この中にあるsrc/assert.jsを使います。その上でtype-assertionsオプションとtype-assertion-moduleオプションを使いましょう。
# type-assertionsとtype-assertion-moduleオプションを使う、moduleの方にはassertライブラリへのpathが必要。 $ traceur --type-assertions --type-assertion-module=assert/src/assert --experimental --out types_compiled.js --script types.js
この後、types_compiled.jsを実行すると、以下の様なエラーが出ます。
Error: ModuleEvaluationError: 'Error: Invalid arguments given! - 1st argument has to be an instance of string, got 1 - 2nd argument has to be an instance of number, got "hoge"'
これにより、引数がアンマッチしていることが警告から分かるようになります。
Annotations
メタ情報をアノテーションとして埋め込むことができます。
// this.nameだけつける var SimpleAnnotation = function(){ this.name = 'Simple'; }; var NestedAnnotation = { // this.name と 引数を持つ Args: function(arg){ this.name = 'Simple'; this.arg = arg; } }; // クラスにAnnotationを付ける @SimpleAnnotation class Foo { constructor() { // 値はannotationsプロパティから得る // [{ name: 'Simple' }] console.log(Foo.annotations); } // 引数 barを入れる @NestedAnnotation.Args("bar") bar() { } } var foo = new Foo(); foo.bar(); // bar をprototypeから得る // [ { name: 'Simple', arg: 'bar' } ] console.log(Foo.prototype.bar.annotations);
実行すると@から始めたAnnotationをインスタンスの中とインスタンスの外側からも値を見ることができるようになります。
実はTypesやAnnotaionsは現在Angular v2.0の開発時に使っている機能のようです。型情報やアノテーションが付けられた方が開発効率が良いらしく、次のES6にあわよくば入れたいが、無理ならES7、みたいな位置づけで提案しようとしているんじゃないかと推測してます。
Annotationを付けることでAngular v2.0にどういう機能が加わるのか少し楽しみではあります。
第二章まとめ
- ES6で提供される機能一覧
- ES7で提供される機能一覧
第三章 traceur compilerの使いどころと類似ツール
traceur compilerのイケてないところ
ここまで学んできて、個人的にtraceurイケてないと思うところは3つほどあります。
- traceur専用のランタイムスクリプトが必要
- 実行速度が遅くなる可能性がある
- 出力されるコードが読みづらい
traceur 専用のランタイムスクリプトが必要
正直一番最初に学んだ時におもったのがこれで、「ES5にトランスパイルしてくれると言ってもそのまま実行できるコードが出力されるわけじゃないのか。。。」と思いました。runtimeはそこまで複雑なことをしている訳じゃないんですが、このruntimeがないと動きません。
destructureとかblocking scopeを使うとどうしてもトランスパイル後の実行時にES5では検証されない値にアサーションを追加する必要があります。
この辺りは実装の仕方だと思いますが、そういうアサーションを提供する際に直接ES5にトランスパイルした時のコードに入れるか、別アサーションライブラリとして切り出して利用させるかといった問題が発生します。
traceurでは後者を選択し、ES5トランスパイル後のスクリプトに複雑なことを入れない反面、traceur-runtime.jsを読み込ませることにしています。
アサーション以外にも標準機能の拡張系の処理だったり、generators、PromiseだったりがES6には加わっているため、その手のpolyfillもtraceur-runtimeには加わっています。
実行速度が遅くなる可能性がある
特にletを使った時に顕著なんですが、Traceurのトランスパイル後の速度を測ってみるとやっぱりそこまで速くありません。
この辺りは若干しょうがない気もしていて、traceurのメインゴールはES6を今のブラウザで使えるようにすることなので、
実行速度の改善は今のところ二の次です。とはいえ、実行速度が明らかに落ちるletとかは辛いです。
traceur-compiler側では今のところletはexperimentalなので、正式な機能として提供してません。
またblock scopeを使った時のパフォーマンスissueとかも報告されており、作者のコメントによればもう少し速くする方法はあるようですが、今のところ時間がないので未対応という感じですかね。
出力されるコードが読みづらい
これも割りとしょうがないんですけど、generatorとかlet使うと出力後のコードがかなり複雑になります。letが遅く、experimentalである理由ですね。ここでletを使ったコードの出力結果を見てみましょう。generatorの時に登場したfibonacci関数に再登場してもらい、出力結果を見てみましょう。
// BEFORE // 1000までの値を返すfibonacciを作る function* fibonacci(){ let pre = 0, cur = 1; while (pre < 1000) { [pre, cur] = [cur, pre + cur]; // yieldで値を返す yield pre; } } for (let n of fibonacci()) { console.log(n); }
// AFTER System.register("a", [], function() { "use strict"; var $__3 = $traceurRuntime.initGeneratorFunction(fibonacci); var __moduleName = "a"; function fibonacci() { var $__2, pre, cur; return $traceurRuntime.createGeneratorInstance(function($ctx) { while (true) // whileで無限ループさせて各種状態によって次のステップに進むか値を返すか例外を投げるか決めてる // ちなみにJSXもgenerator/yieldでは似たようなことしてる。 switch ($ctx.state) { case 0: pre = 0, cur = 1; $ctx.state = 9; break; case 9: $ctx.state = (pre < 1000) ? 5 : -2; break; case 5: ($__2 = [cur, pre + cur], pre = $__2[0], cur = $__2[1], $__2); $ctx.state = 6; break; case 6: $ctx.state = 2; return pre; case 2: $ctx.maybeThrow(); $ctx.state = 9; break; default: return $ctx.end(); } }, $__3, this); } // ここがforループでletを使った時に問題になりそうなコード for (var $__0 = fibonacci()[$traceurRuntime.toProperty(Symbol.iterator)](), $__1; !($__1 = $__0.next()).done; ) { try { // まずここで例外を発生させる! throw undefined; } catch (n) { // catch節の中で例外用の変数nに値を代入して使っている。 // 多分ここがループで使うとものすごく遅い。 // このcatch節の外でletで宣言したnは見えない、なぜならn変数はこのcatch節の中でしか有効じゃないから。 { n = $__1.value; { console.log(n); } } } } return {}; }); System.get("a" + '');
とまぁこんな感じでものすごく見難いコードになります。かろうじて中でやってることは分かりますが、letをforループ内で使うと毎回例外を投げるという酷いコードになってしまうので、今のところexperimentalというのも頷けます。
というわけで、
runtimeスクリプトが必要なのは実装方針なのである程度しょうがないとして、traceurでexperimentalとされている機能を使うのはあまり得策ではありません。
機能的にも性能的にも安定しなくなります、もしもexperimentalな機能を使うなら、完全に学習用だと割りきって使う方がよいでしょう。
その他の機能もシビアに性能を求める場所では使わないほうが良いでしょう。generatorsの生成コードを見てもらって分かるかと思いますが、かなり富豪的に実現しようとしているので、それよりは愚直に書いた方が性能は上でしょうし、それは他の機能においても同様のことが言えます。
「現時点では」まだ仕様も固定されていないES6に手を出そうとしている時点で人柱になる覚悟はないといけないし、明日には仕様が変更される可能性があることを考慮しつつ使うことをオススメします。
それでもES6の仕様が固定された上で生成されるコードの性能面が安定するなら学習用じゃなく、一般的に利用してもよいと思っています。長期的に見ればES6 + traceurで書いて、今のうちにES6への学習コストを払っておく事に利点はあると感じています。
類似するツール
実はtraceur-compilerだけじゃなくて、後発で同様のことを実現するツールはいくつかあります。今のところ機能面ではtraceurが一番多いですが、human readableなコードを生成する点やruntimeエンジンが不要な点でtraceurよりも優れていると思えるものもあります。
- es6-transpiler traceur-compilerが専用のruntimeエンジンが必要なのに対してruntimeスクリプト不要のjavascriptを出してくれる。また、outputされるコードの中身も読みやすい。letの時にはtry-catchを使わないことが明記されており、transpile時に警告を出してくれる。ただし、symbol, generators, moduleといった機能は未実装。
第三章 まとめ
- traceurのイケてない所
- traceurの使いドコロ
- 類似するツール
まとめ
- traceur-compilerの概要を説明
- traceur-compilerがサポートしている言語仕様を説明
- traceur-compilerの使いドコロを説明
- 類似するツールについて説明
ES6の機能群を見ているとJavaScriptが割りとモダンで新しい言語になろうとしている反面、各ブラウザベンダの機能サポートに差があるので、クロスブラウザでサポートする場合、こういうtranspilerが今後必要になってくるのではないかと感じています。
これを見て少しでもES6の機能に興味が出てくれると幸いです。
参考資料
*1:runstant++
*2:どうでもいいことだけど、この人がid:teppeisさんにものすごくアイコンが似ててビックリする
#寿司js 、#桜js に行ってきた感想と居心地が良いコミュニティを作ることに関して
teppeisさんのブログエントリを読んで、そういえば全然寿司jsと桜jsについて書いてなかったなと思ったので書く。
寿司js
寿司jsはいつもtwitter上では絡みのあるteppeisさんと一回話してみたかったazu_reさん、imayaさんと飲んでみたいというモチベーションから寿司食べに行こうって誘ったのが始まりでした。結局飛行機の都合でteppeisさんは来れなかったものの、hokacchaさんやyoshikikojiさんやkyo_agoさんが集まってワイワイした飲み会LT大会に。
今必死で寿司用のブログを書いてる。ちなみに寿司.jsというのは、僕がteppeisさんとazu_reさんにライブラリ情報更新ツイートいつも感謝してますという旨の連絡したらteppeisさんから寿司を強請られたので、開催した飲み会です。飲み会のはずだったんやで。。 #寿司js
— Yosuke FURUKAWA (@yosuke_furukawa) March 31, 2014寿司jsは以下のエントリを参考にしてもらえればいいかと。
寿司jsでしたLT
僕が寿司jsでした話は、チーム開発してて依存ファイルに変更あった時にライブラリインストールし直す必要あるんだけど、みんなどうしてんの?っていう話で、ちょうど事前にブログ書いてたので、それを解決するためのツール、hookinの紹介でした。
git pullでファイルに変更があったら特定のコマンドを実行する。 - from scratch
毎回起動する時にインストールしなおして解決するとか、代替策は出たんだけど、弊社ではgithubにはあるけど、npmにpublishされてないモジュールが多くて、そういうモジュールをpackage.jsonに記述すると、npm が変更があったかどうかを検知できずに毎回installが実行されるから無駄が多いんだという議論になり、この辺、npmが頑張ってくれるといいよね、っていう話をした。
寿司jsの感想
Promise、package.jsonの話、WebComponentsの話、結婚式LTの話、dockerの話、Firefox、vuejs、hueの話と盛り沢山ですごく楽しかった。ガチなトークでした。参加できなかった人 (@teppeis 含む)は第二回で会いましょう
#寿司js
— Yosuke FURUKAWA (@yosuke_furukawa) March 31, 2014まぁこんな感じだった。どちらかと言うとお互いが共通項目について深く話すというよりもお互いの業界を肴に便利情報や自分の興味を語り合うって感じだった。
LTの内容は全部面白かったんだけど、特に面白かったのは、mozaic.fmでも話してたWebComponentsの話 by hokacchaが面白かった。
皿属性消すとお皿見えなくなる #寿司js pic.twitter.com/AdafxYGyy7
— Yoshiki Kojima (@yoshikikoji) March 31, 2014x-sushiっていうカスタムタグを作って皿属性を消すと皿を見えなくしたり、うにをマグロに変えたりとデモをしてくれた。モジュラビリティを高める話もあったし、ちょうどmozaic.fmで話してたパッケージマネージャの話もチラホラ出てて面白かった。
桜js
花見しながらハッカソンしたいよね、っていうノリからkyo_agoさんが主体となって呼びかけてくれた飲み会LT大会です。結局天候の都合によって花見ハッカソンは叶わなかったんだけど、居酒屋でLT大会になった。
寿司jsの時にtkihiraさんに会いたいって言っていた人が多数いたのでtkihiraさんを入れ、飛び入りでJxckさんとotiai10さんを交えて開催した。
桜jsでしたLT
僕が桜jsでした話はNode.js v0.12で変わることの話だった。tracing apiやchild_processのsync系 APIの話、つい最近入ったPromise, WeakMap, Object.observeが使えるようになるっていう話をした。
基本的には前のNode学園で発表した話と当日にあったpull reqの話だった。
これからのNode.jsの話をしよう // Speaker Deck
https://github.com/joyent/node/pull/7394#issuecomment-39276195
tracing apiとかWeakMapとかメモリの解放がやりやすくなっていいよね、っていう話をした。
桜jsの感想
#桜js おもしろかった、さくらのクラウド、node v0.12、WebGL、HTMLのレイアウトとWebの定義、coffeescriptの踏み絵、closure compiler、formタグの今後、MクライアントサイドMVC dis、power assertの話が出た。
— Yosuke FURUKAWA (@yosuke_furukawa) April 2, 2014みんな今後のWebについての話がすごく熱かった。みんな背景違うのにcoffeescriptの時だけ一つになれた感があった #桜js
— Yosuke FURUKAWA (@yosuke_furukawa) April 2, 2014というわけで、teppeisさんが書いてくれている通り、深い議論ができて物凄く面白かった。
みんながしたLTと問題提起が良かったんだと思う。
居心地が良いコミュニティを作ること
桜jsと寿司js、すごく居心地が良かった。コンテキストが大体一緒で、皆一定以上の深い造詣や知識があってそういう人達が集まってワイワイ議論するのって物凄く楽しくて有効で、大きめの勉強会行って話し聞いて帰ってくるよりも得られたものは大きかったと思う。
PUT/DELETEの議論の深化もそうだし、クライアントサイドMVCに対するdisもそう。気を遣う事無く自分の思っていることをぶつけられる場っていうのはやっぱり楽しい。
んで、自分は今年の1月からNode.jsユーザーグループの代表なんですけど、Node.jsってフロントエンドツールとしてもバックエンドサーバとしても使われてて、活躍の舞台が広くて必然的にたくさんの人が集まってくれてて嬉しい限りなんですが、大人数になればなるほどコンテキストが大体一緒で深い知識や造詣を持っている人達とコミュニケーションするのってどんどん難しくなってきてるなと感じています。
しょうがないんですけど、東京Node学園に来てもらって発表だけ聞いて帰った時に得ているものと桜js、寿司jsで深い議論した時に得ているものって違うんですよね、質も量も。
Node学園で発表している内容ってのは、そこまで本質とは関係なくて、今のNode.jsで起きている最新の事をsyncする程度で考えてもらえれば良いかなと思っているんです。本質は最後にある懇親会だと思うんですよ。そこで自分が今抱えている問題や作ろうとしているアプリケーションのことを知見者に話したり、深い造詣を持っている人に聞くっていう、思っていることをぶつけられる場にしたいなと思うんです。
発表やLTはそのためのものであって、コミュニケーションのためのタネです。時間の都合上しょうがない人も多いと思うし、人見知りの人もいるのでしょうがないと思うんですけど、発表だけ聞いて懇親会に出ないというのは自分の思っていることをぶつけられる機会を失っているって言うことなので非常に損だと思うんです。
という訳で、今度Node学園 4/24(木) 19時から渋谷ヒカリエで実施します。
コミュニケーションしてみたいけど、詳しい人が誰なのか分からないって言う方や知り合いがいないっていう人は僕が懇親会で話している輪に勝手に加わって、僕に質問や思いの丈をぶつけて下さい。僕より詳しい人がいればその人を紹介しますし、答えられる範囲で話します。
I'm looking forward to talking with you :)
Yet Another JSONなJSON5の紹介とそれのjsxバインドを作ったこと
さて、JSON5についての紹介です、みんなjsonを使って色んなリソースを表現すると思いますが、jsonって色々と不便ですよね。
よく挙げられるjsonの不満:
- ケツカンマが使えない
- コメントが入れられない
- keyに必ずquoteが必要
などなど。
この手の話はよくあるんですが、これは仕様で決まってしまっていることなのでどうしようもないです。
この手の話が出る度に色んな解決策があります。jsonじゃなくてyaml使おうとか、csonいいよ、とか、jsonでparseできなかったらevalしてjavascriptオブジェクトにしちゃおうとか。
んで、もう一つの解決策として、JSON5っていうYet AnotherなJSON形式があるわけです。
これ使うと普通のJSONはJSONとしても読み込めるし、上にある、コメントやケツカンマ、ダブルクオートの問題も解決されます。どうしてもコメント入れたい場合やケツカンマを入れたい時は使うのもいいのかな、という紹介です。
// コメントが書ける { // ダブルクオート不要 foo: 'bar', while: true, // 複数行の文字列も\で区切って書ける this: 'is a \ multi-line string', here: 'is another', // インラインコメントも /* ブロックコメントも可能 */ // 16進数入れたり (内部的に10進数に変換される) hex: 0xDEADbeef, // 小数点の0を省いたり half: .5, // 明示的に+-を書いたり delta: +10, to: Infinity, // Infinityもいける finally: 'a trailing comma', // もちろん配列書いたり oh: [ "we shouldn't forget", 'arrays can have', 'trailing commas too', // ケツカンマも対応。 ], //ここにもケツカンマ、ちなみに日本語もコメントも可 }
使い方は簡単で、npmで入れたりbowerで入れれば後は普通のJSONと同じ。
// parseする時 var obj = JSON5.parse(json5); // 文字列化する時 var str = JSON5.stringify(obj);
JSON5のjsxバインド
JSON5のbindingとか簡単にjsxで作れそうなので、一瞬で作ってnpmで公開しました。
GitHub: https://github.com/yosuke-furukawa/json5x
npm : https://www.npmjs.org/package/json5x
使い方
$ npm install json5x
import "json5x/json5.jsx"; class _Main { static function main(args:string[]):void { var testData = """ // コメントが書ける { // ダブルクオート不要 foo: 'bar', while: true, // 複数行の文字列も\で区切って書ける this: 'is a \ multi-line string', here: 'is another', // インラインコメントも /* ブロックコメントも可能 */ // 16進数入れたり (内部的に10進数に変換される) hex: 0xDEADbeef, // 小数点の0を省いたり half: .5, // 明示的に+-を書いたり delta: +10, to: Infinity, // Infinityもいける finally: 'a trailing comma', // もちろん配列書いたり oh: [ "we shouldn't forget", 'arrays can have', 'trailing commas too', // ケツカンマも対応。 ], } """; var testJson = JSON5.parse(testData); log testJson; } }
ちなみに、JSXの新しいバージョン(0.9.77)以降ではデフォルトでnode_modules/libの下を検索対象にしてくれるようになったので、命名規則さえ守れば簡単にnpmからモジュールとして使えます。
ノンプログラマのためのJavaScriptはじめの一歩を読みました。
")
ノンプログラマのためのJavaScriptはじめの一歩 (WEB+DB PRESS plus)
- 作者: 外村和仁
- 出版社/メーカー: 技術評論社
- 発売日: 2012/11/07
- メディア: 単行本(ソフトカバー)
- 購入: 3人 クリック: 60回
- この商品を含むブログ (3件) を見る
紹介
初心者本のあるべき姿を体現した本。
スライドショーという一つのお題を突き詰めて説明し、最初はDOMを使った操作を解説し、最終的にはjQueryを使ったやり方で改善していく。
変数の説明からif文、for文といった話、jQueryの使い方まで載っている。
プログラムを学びたいけど、何から手を付けていいかわからない、という方には本当にうってつけ。
javascriptの良さの一つとして、コードを書けば、ブラウザだけで動作確認できる所が挙げられる。
JavaにしてもRubyにしても環境構築のためにやらないといけないことはあるし、その点、Javascriptは特に環境構築は不要で、コードをHTML内に書けばブラウザでそのまま動作する。Javascriptで初めてプログラムを学ぶのが意外にいいんじゃないかと思っているのはこの導入への難易度の低さ。そして本書はそれを十二分に活かしている。
特にプログラムの読み方と組み立て方の章では、console.logでの簡単な確認方法からキャッシュによる効率化までTipsや気をつけるべき考え方が載っててかなり参考になる。
あと、実は
著者の外村さんこと、 @hokaccha さんとは色んな勉強会で頻繁に出会う友人の一人です。誕生日の日にサインまで書いてもらってしまいました。

だからといって特に贔屓した意見を述べているつもりはなく、実際に"はじめの一歩"をjavascriptでキメたい人にとっては読んだほうがいいです。
あとどうやら今度、著者の方からのセミナーが開かれるようです。
『ノンプログラマのためのJavaScriptはじめの一歩』セミナー|CREATIVE VILLAGE|クリーク・アンド・リバー社
本を持っていけばサインが貰えるかも。読んで言ってみることをオススメします。