【翻訳】リッチなWebアプリケーションのための7つの原則
はじめに
この話はGuillermo Rauch氏が書いたhttp://rauchg.com/2014/7-principles-of-rich-web-applications/ という記事の翻訳です。許可を得て翻訳しています。
ここ最近Web業界を賑わしているSingle Page Applicationの必要性、HTTP2/SPDYといった技術、リアクティブプログラミングやIsomorphicデザインという考え方について包括的にまとめたすごく良い記事になっております。
最初に断っておきますが、ものすごく長いです。各セクションがわかれているので時間がない方はセクションごとに書かれたtl;DRとまとめを読むだけでも参考になるかと思います。
ちなみに明日のNode学園祭には、本記事を記述したGuillermo Rauch氏が見えるので、そこで詳しく聞いてみるのもいいのではないでしょうか。
リッチなWebアプリケーションのための7つの原則
これは2014年の8月に開催されたBrazilJSで話したプレゼンテーションを元にまとめたものです。私がUXやパフォーマンスに関して最近ブログに書いて まとめたアイデアのいくつかで構成されてます。
UIコントロールをJavaScriptで行っているウェブサイトのための、7つの実践可能な原則を紹介しようと思います。この原則は私がWeb開発者として経験したことに基づいているだけじゃなく、World Wide Webの長期ユーザーとしての経験から作られています。
JavaScriptはフロントエンド開発者にとっては無くてはならないツールになっています。その使用方法はサーバーやマイクロコントローラーなど、色んな領域に拡張されています。
しかしウェブにおいてJavaScriptの正確な役割や利用方法についてはたくさんの疑問や謎があります。多くのフレームワークやライブラリ作者においても同じことが言えます。
- historyやnavigationやpage renderingといったブラウザの機能をJavaScriptで置き換えたほうが良いのか?
- backendで多くの処理をするのはオワコンなのか? それとも全てのHTMLをレンダリングするべきなのか?
- Single Page Applicationは未来なのか?
- JSはサイトのページを拡張するためのものなのか、アプリケーションとしてページをレンダリングするためのものなのか?
- PJAXやTurboLinksのようなテクニックは使ったほうがよいのか?
- ウェブサイトやウェブアプリケーション感のはっきりした違いとは何なのか? そもそも違いなんてあるのか?
これらの疑問に対して以下のように回答してみました。私のアプローチはUXの観点からJavaScriptの利用方法を調査する、という方法を取りました。特に、エンドユーザーにとって興味のあるデータを取得させるため、どうやって時間を短縮しようとしているのかといったアイデアに強くフォーカスを当てて調査しました。ネットワーク基礎を初めとして、未来予測まで幅広く記述しました。
- サーバーがページをレンダリングするのは任意ではない (必須である)。
- ユーザー入力に迅速に対応しよう
- データの変更に反応しよう
- データ変更をサーバーとともにコントロールしよう
- historyを壊すべきじゃない、historyを拡張しよう
- コードの更新をPushしよう
- 振る舞いを予測しよう
1. サーバーがページをレンダリングするのは任意ではない (必須である)。
tl;DR: サーバーレンダリングはSEOだけのものじゃなく、性能を向上させるためのものです。JavaScriptやCSS、APIリクエストを取得する時にラウンドトリップが起きる事を考慮して設計すること。将来的にはHTTP 2.0でリソースをサーバープッシュする事も検討しておくこと。
これまで、このトピックは一般的に対立構造(VS構造)として語られてきました。例えば、 "Server Side Rendered Apps vs Single Page Apps"といったような形です。もし我々がUXや性能をベストまで最適したいと思ったら、サーバーサイドレンダリングとSingle Page Appsのどっちかを取ってどっちかを諦めるのは良いアイデアとはいえません。
その理由はわかりやすく単純です。インターネットを介して送信されたどんなページにも理論的なスピードの限界があるからです。この限界はStuart Cheshireによって書かれた有名なエッセイ、 "It's the latency, stupid"によって説明されています。
StanfordからBostonまでは4320kmある。
真空状態の光の速度は 300 x 10^6 m/s.
ファイバーの中での光の速度は大雑把に言うと真空状態の 66%。
ファイバーの中での光の速度は 300 x 10^6 m/s * 0.66 = 200 x 10^6 m/s
ボストンへの片道で遅延は 4320km / 200 x 10^6 m/s = 21.6ms.
ラウンドトリップタイムはBostonから戻るまでに43.2ms.
現在のインターネット環境でStanfordからBostonにpingを送った時は大体85ms
そのため: インターネットのハードウェアは光の速度の2倍くらいかかることになる。
BostonとStanford間の85ms のラウンドトリップタイムは将来的に改善されていくでしょう。もしかしたら今すぐにでも実験すれば改善は見られるかもしれません。しかし、BostonとStanford間にはどんなに速くなったとしても約50msほどの理論的な限界値があるということに注意しなくてはなりません。
ユーザーのコネクションにおける帯域幅の制限はものすごく改善されるかもしれません、それが堅調に改善されたとしても、latencyの指している針(限界値)は全く動かないでしょう。ページ上のなんらかの情報を表示しようとする際に。ラウンドトリップ自体の回数を最小化する事が重要になるでしょう。
特に素晴らしいUXやレスポンシブさを提供するためには考えるべきです。
これは特に<script>や<link>タグ以外のマークアップが存在しない、空のbodyタグで構成されたJavaScript駆動のアプリケーションが起動する時に考慮する必要がある問題です。この種類のアプリケーションは "Single Page Application" とか "SPA" の名前で受け入れられています。その名前が示す通り、一つのページしか存在せず、クライアントサイドのコードによって残りの部分を表示します。
URLが打ち込まれたり、linkを辿った際に、http://app.com/orders/にユーザーがページ遷移する、というシナリオを考えてみましょう。その瞬間からあなたのアプリケーションはリクエストを受けて、処理が始まります、そのページを表示しようとするのに重要な情報は既に持っています。例えばdatabaseからの命令をpre-fetchしたり、レスポンスにそれらの情報を含めることができます。ほとんどのSPAの場合、ブランクのページと<script>タグがその代わりに返されます。それからさらに一回のラウンドトリップが行われて、スクリプトの内容が取得されます。さらに、もう一度ラウンドトリップが発生しレンダリングするためのデータが取得されます。
ほとんどの開発者は意識的にこのトレードオフを受け入れています。なぜなら彼らはその複数回のネットワークホップがたかだか一回しか発生しない事を確認しているからです。つまり、彼らのユーザーはscriptやstylesheetのレスポンスヘッダーに適切なキャッシュ情報を埋め込んでいるため、キャッシュにヒットされれば毎回のホップは発生しない事になります。一度だけロードされ、ほとんどのユーザー操作(他のページに遷移するといったような操作)をハンドリングできれば、追加のページやスクリプトのリクエストを発行する必要はありません。これが受け入れ可能なトレードオフであるということは一般的に認識されています。
しかしながら、キャッシュがあったとしても、scriptパースや評価にかかる時間が考慮された際にパフォーマンス上の障害になることがあります。 "jQueryはMobileにはでかすぎじゃね?" という記事では、jQuery単体であっても、mobile browserが確認するためには何百ミリ秒のオーダーがかかることが記述されています。
不幸なことに、scriptがロードされている間、ユーザーに対して何のフィードバックも帰ってこない事があるのです。この結果、ブランクのページが表示され、直後に全ページがロードされて描画されます。
最も重要な事として、我々開発者はインターネットデータ通信 (TCP) の開始が遅いということを常に意識しているわけではありません。TCPの開始が遅いことによって一回のラウンドトリップで全てのscriptをfetchされるようなことはまずありません。それだけじゃなく、さらに悪い状況を作ることもあります。
TCP接続は初期ラウンドトリップのハンドシェイクとともに開始されます。もしあなたがSSLを使っているのであれば、2回のラウンドトリップ*1が行われるでしょう。データ送信がサーバーから開始されるのは、ゆっくりと段階的に行われることに成ります。
輻輳制御のメカニズムはTCPプロトコルの中ではスロースタートと呼ばれています。TCPプロトコルはデータを送る際に一度に送るセグメントの数を徐々に増やして送ります。SPAにとってこの仕組みには2つの深刻な影響があります。
1. 巨大なスクリプトがあると予想よりもはるかにダウンロードに時間がかかることになります。
Ilya Grigorikが書いた"ハイパフォーマンスブラウザネットワーキング"で説明されている通り、"クライアントとサーバー間で64KBのスループットを届けるだけでも4回のラウンドトリップと何百ミリ秒ものレイテンシーが発生する。"事になでしょう。この例では、LondonとNewYorkの間の長いインターネット接続が考慮されているが、TCPが最大パケットサイズに届くようになるまでに225msかかると言われています。
2. TCPスロースタートの法則は初期ページのダウンロードにも適用されます、初期ページには全てのページの中で一番重要な"ページをレンダリングするのに必要な情報"があります。 Paul Irishはかれの発表資料、"Delivering the Goods"の中で、初期の14kbが如何に重要かを語っています。サーバーがラウンドトリップ内で送信できるデータ量に関するわかりやすいイラストを見て下さい。
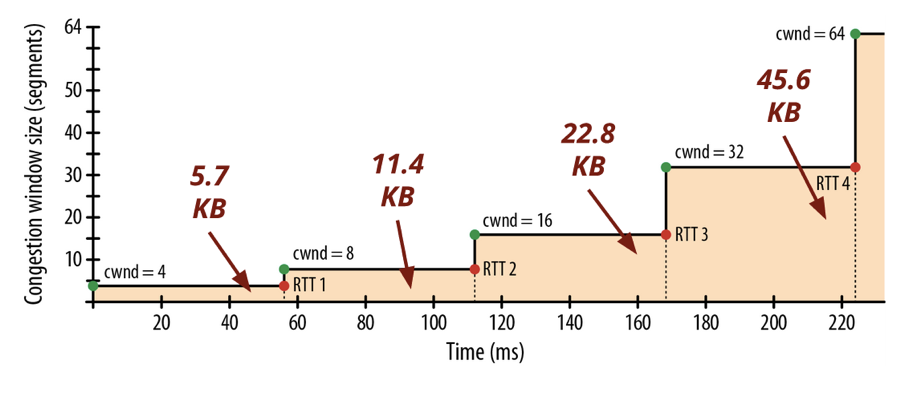
このウィンドウサイズに合わせてコンテント*2を配信するウェブサイトはかなりレスポンシブに見えることでしょう。実際、高速なサーバーサイドアプリケーションを書いている多くの開発者にとって、JavaScriptは不要であると考えられていたり、控えめに使われている事があります。もしアプリケーションが高速なバックエンドとデータソースとユーザーに近い場所にサーバーがある(CDNを利用している)場合、このバイアスはかなり強くなります。
コンテントの表示が高速化され、補えるようになれば、サーバーの役割はアプリケーション特化なものになっていくでしょう。そのソリューションは常に"サーバーで全ページをレンダリングすればいい"という程に単純にはなりません。
いくつかの場合において、本質的じゃないページのパーツは初期レスポンスから外して、クライアントによって後で取得させた方がより良くなるでしょう。いくつかのアプリケーションは迅速にレスポンスを返すためにそのページの外枠を先にレンダリングしようとします。そうした後で並列にページの異なる部分をfetchします。これは遅くてレガシーなバックエンドサービスの場合には素晴らしい反応を見せるでしょう。いくつかのページにおいて、"above the fold(スクロールしなくても見えるページ)"のプリレンダリングをしておくことは有効な選択肢と言えます。
セッション、ユーザー、URLごとにサーバーが持っている情報に基づいてscriptやstyleの存在意義を評価する事はかなり重要です。例えば、orderをソートするスクリプトは/settings ページにあるよりも /orders ページにだけ存在するほうがいいでしょう。
直感的じゃないかもしれませんが、"構造を作るCSS"と"skinやテーマを決めるCSS"間の違いを作っておいたほうが良いかもしれません*3。前者はJavaScriptコードから利用されるため、ロードされるまでブロックされるべきですが、後者は非同期でロードされたほうが良いでしょう。
ラウンドトリップが複数回発生することによる障害を受けないSPAのシンプルな例として、StackOverflow in 4096という名前のStackOverflowのクローンがあります。4096バイトだとTCP接続の最初のハンドシェイクラウンドトリップの後で理論的には配信されることができます。これはレスポンスの中で全てのアセットをインラインにすることによってcacheabilityを犠牲にして実現されています。SPDYもしくはHTTP/2のサーバープッシュがあれば、理論的にはクライアントのコードをキャッシュ可能な状態でシングルホップで配信する事ができるようになるでしょう。当分の間はページの一部分もしくは全てのレンダリングをサーバーでやることが複数ラウンドトリップを回避するための一般的なソリューションになるでしょう。
ブラウザとサーバー間でレンダリングするコードを共通化でき、scriptsとstylesをロードするツールを提供するシステムはウェブサイトとウェブアプリ間のラフな違いをなくしていくでしょう。両者とも同じUXの原則に従うことになります。ブログとCRMは基本的にそんなに違いはありません。両方共URLがあってnavigationがあり、ユーザーにデータを表示します。クライアントサイドの機能に強く依存しているspreadsheetのようなアプリケーションでさえ最初にユーザーにデータを表示する必要があります。つまりネットワークのラウンドトリップ回数を最小にすることが最も重要になるという事です。
パフォーマンスに関してのトレードオフによって、ウェブは複雑さをどんどん増していっています。複数ラウンドトリップにも非常に関係があるように見えます。
JavaScriptとCSSによるテクニック、Tips*4は時間とともに追加されていました。そういうテクニックの人気や評判も時間とともに増加してきました。
今後はそういったテクニックには別な方法があることを理解できるでしょう。SPDYやQUICに見られる改善中のプロトコルによってこれらのいくつかは解決され、さらにアプリケーションレイヤーにも多くの利点を発生させる事になるでしょう。
初期のWWWやHTMLの設計に関する初期の議論のいくつかを参考にするとこれを理解しやすくなるでしょう。特に1997年の<img>タグをHTMLに追加する事を提案しているこのメーリングリストのスレッドの中で Marc Andreessenが高速に情報を提供することの重要さについて度々話をしています:
"もしもドキュメントがその場その場で断片化されなければならないのであれば、複雑さを生むことになってしまうだろう、そして例えそれらが限定的だったとしても、私達はこの複雑な方法で構造化されたドキュメントの性能にぶつかることを体験し始めることは明らかだ。これは本質的にWWWのシングルホップの原則をドアの外に投げ出している (IMGタグもそれをすることになる)。本当に我々はそれをしたいのかどうか胸に手を当ててみたらどうだろうか?"
2. ユーザー入力に迅速に対応しよう
tl;DR: JavaScriptを利用すればネットワークレイテンシーを隠せるようになります。これをデザインの原則として適用すれば、あなたのアプリケーションから"ロード中..."のメッセージやスピナー(ぐるぐる)を削除することができるようになるでしょう。PJAXもしくはTurboLinksはこの"the perception of speed" (スピードの錯覚) を使って改善するチャンスを失ってしまうでしょう。
最初の原則はあなたのウェブサイトに対してレイテンシーを最小化することの考え方に関するものでした。
とは言っても、サーバーとクライアント間を往復する回数を最小化するためにどれだけ努力を惜しまなかったとしても、どうにもならない事があります。ユーザーとサーバー間の距離によって得られる理論上最小のラウンドトリップタイムが発生してしまうことは避けようがありません。
貧弱だったり予測できないようなネットワークの品質も重大な事項の一つになるでしょう。もしネットワーク接続がそこまで品質の良いものじゃなかったとしたら、パケットの再送が発生するでしょう。結局、取得するのに何回もラウンドトリップが発生してしまうような結果になる事は予測できます。
UXを向上する事に対してJavaScriptの最適な強みはこの部分にあります。クライアントサイドのコードはユーザーインタラクションを強く惹きつけておくことで、このレイテンシーの問題を隠すことができるようになります。スピードの錯覚を作ることができます。人工的にレイテンシーが存在しないように見せようとすることもできます。
ベーシックなHTMLウェブをちょっとだけ考えてみましょう。ハイパーリンクまたは <a>タグを通してドキュメント同士をつなぐことができます。リンクがクリックされた時、ブラウザは予期できないほど時間がかかる可能性があるネットワークリクエストを発行し、そのレスポンスを取得し、処理し、新しい状態に最終的に遷移します。
JavaScriptではユーザーの入力後に即座に実行する事も、少し送らせてから楽観的に実行する事もできます。リンクやボタンの上でクリックした時に、ネットワークを使わずに即座に反応するという事もできます。有名な例としてはGmail (またはGoogle Inbox)が挙げられます。emailをアーカイブするとUI上で即座に反応が返ってきます。その後、非同期に処理をサーバーに送っています。
フォームの場合、submitしたあとでレスポンスとしてHTMLを待つ代わりに、ユーザーがenterを押したあとで即座に反応することが可能です。より良い例として、Google Searchのような動きが当てはまります。下矢印キーを押し続けるとユーザーに即座に反応を返します。
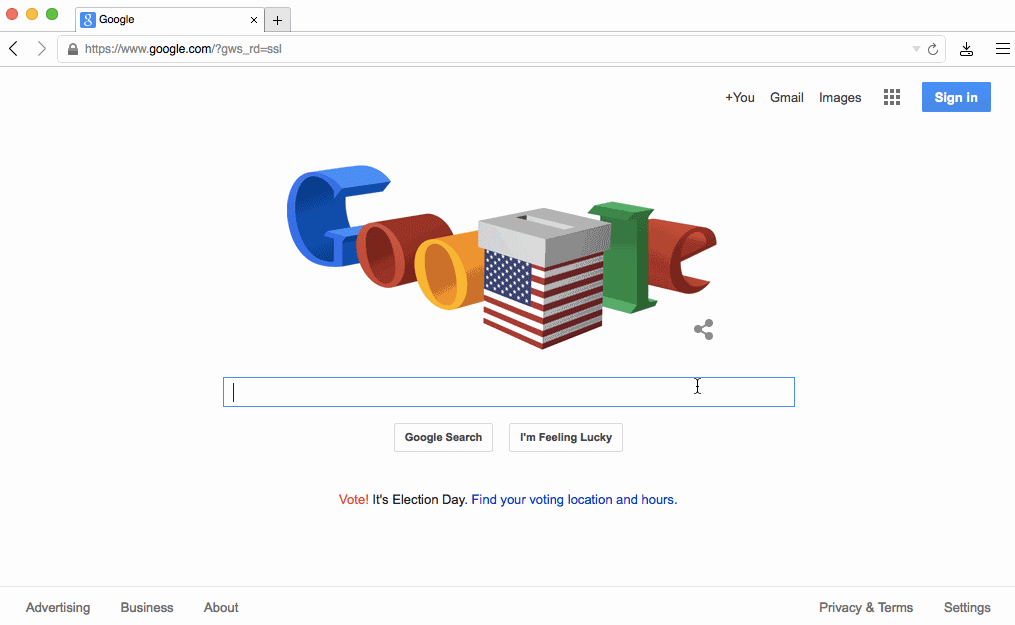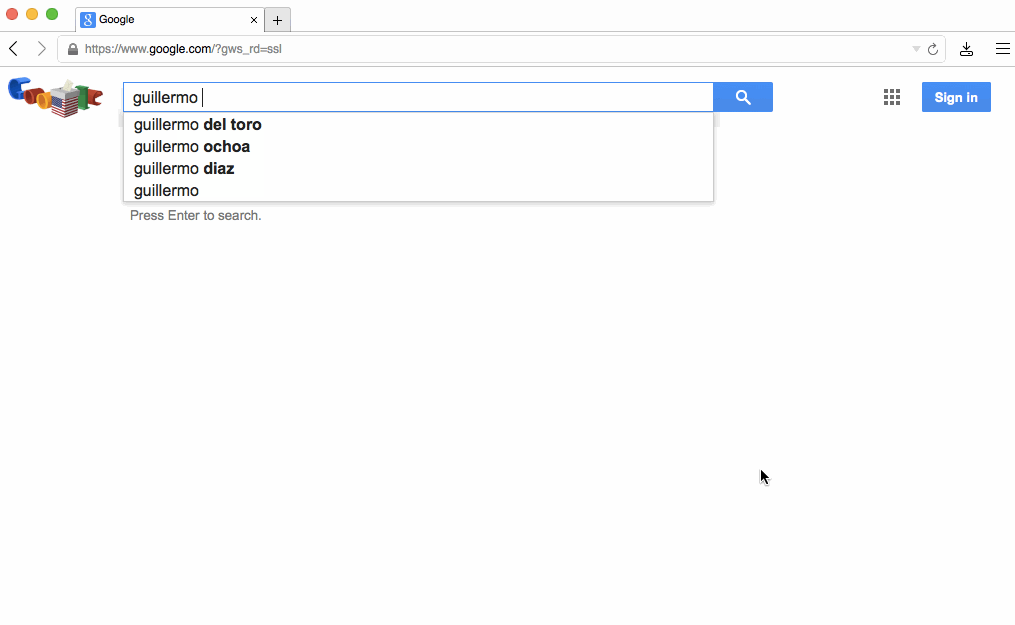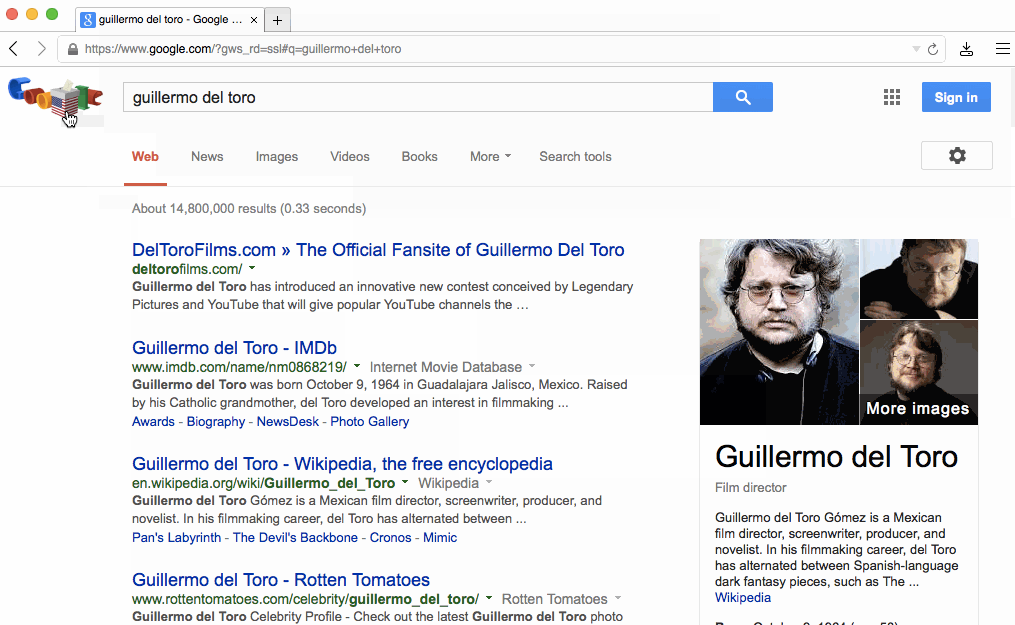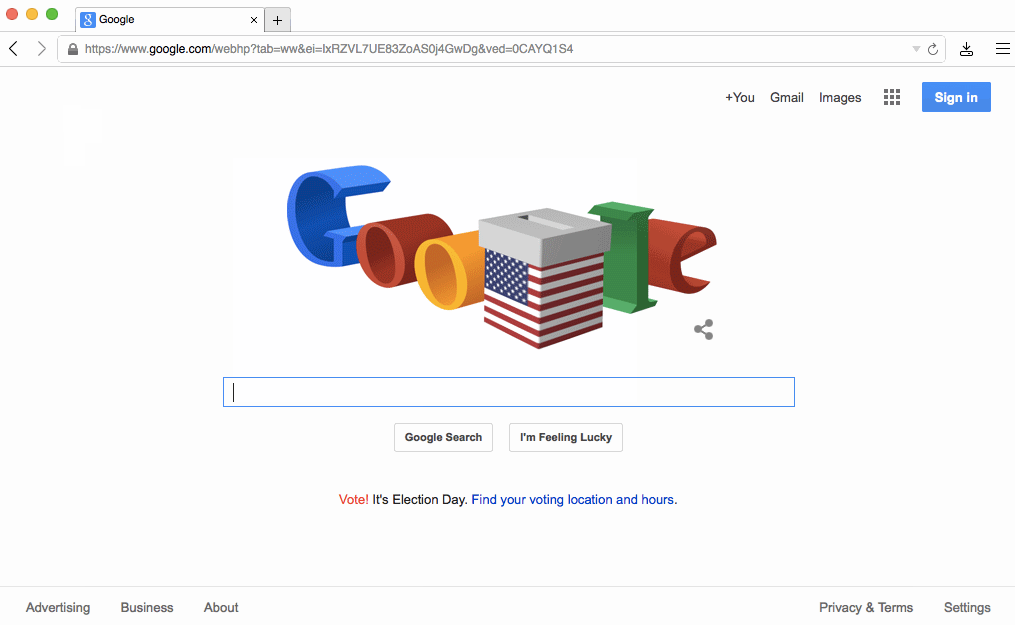
その特別なふるまいはlayout adaptationと呼ばれるものの例です。基本的なアイデアはページの初期状態が次の状態のレイアウトについて"知って"おり、遷移する前にそのページに入れるべきいくつかのデータがあれば可能になります。データを事前に持つことは"楽観的"と言われています、なぜなら入力によってはデータが全く来ない時にかわりにエラーが表示されるリスクがあるからです。しかし、そのような場合は明らかに少ないと言えるでしょう。
Googleのホームページは特にこの試みに適しています。なぜならこの進化は私達が議論してきた最初の2つの原則を解説するからです。
最初に、www.google.comへTCP接続をした時のpacket dumpを解析すると、リクエストが発行された後で一度に全体のホームページを送っていることが確認できると思います。接続をクローズするまで含めた全体はSan Franciscoにいる私には64msかかります。初めから今までそういう傾向にあります。
{kind=link}
2004年の後期にGoogleはas-you-typeサジェスト機能(キーボートをタイプした瞬間から検索する機能((Gmailのように20%プロジェクトとして作られました)))を提供し、JavaScriptの利用方法を開拓しました。これは後にAJAXを作るきっかけになりました。
ここでちょっとGoogle Suggestを見てみましょう、あなたがタイプした瞬間にページのリロードや待ち時間もなく即座にサジェストされる単語がアップデートされることに注目してください。Google SuggestやGoogle MapsはAdaptive Path社がAjaxと名づけた技術を使って Web アプリケーションの新しいアプローチを示した2つの例です。
2010年にGoogleはInstant Searchを紹介しました。InstantSearchはJSをフロントにおいてキーを押した瞬間にページリフレッシュをまるごとスキップさせて、"検索結果" レイアウトに即座に遷移するようにしていました。ちょうど上の画像の例のとおりです。
layout adaptationのもう一つの有名な例があなたのポケットにも入っているかもしれません。初期からiPhone OSはアプリケーション作者に default.png の画像を提出させます。これは実際のアプリケーションがロードされるまでの間に即座にレンダリングさせるためです。

この場合、OSがネットワークレイテンシーによる遅延だけじゃなく、CPUによる遅延を考慮し、それを補うために行っています。アプリケーションがロードされる前に初期ロードを早くするためにレイアウト画像を見せることはハードウェア本体の制約としても極めて重要だと考慮されています。
しかしこの技術がマッチしないシナリオも存在します。レイアウトがストアされた画像にマッチしない時、例えば全然レイアウトが違うログイン画面に遷移してしまうといった場合にマッチしません。その影響がどのくらいのものなのかを分析した結果がMarco Armentによって2010年に提供されています。
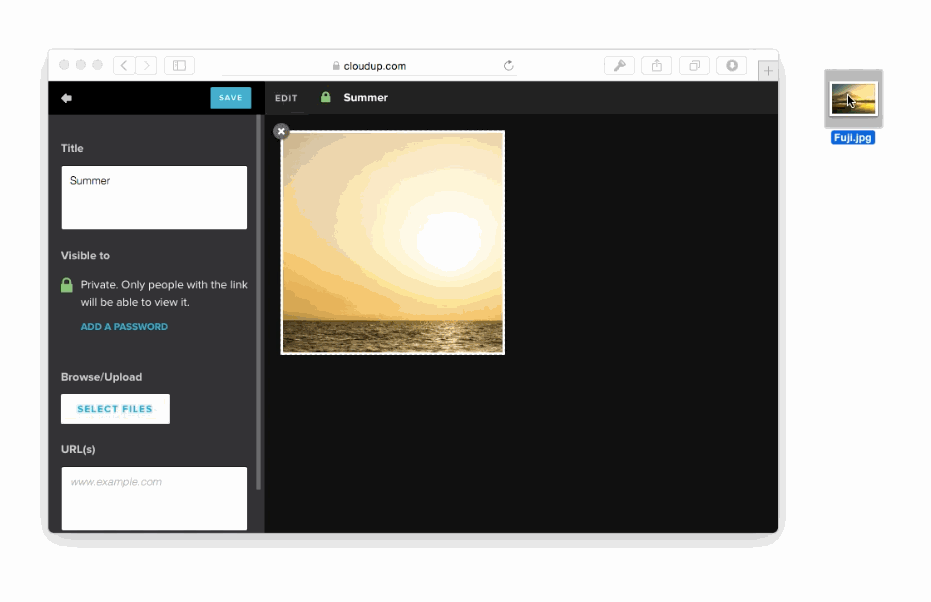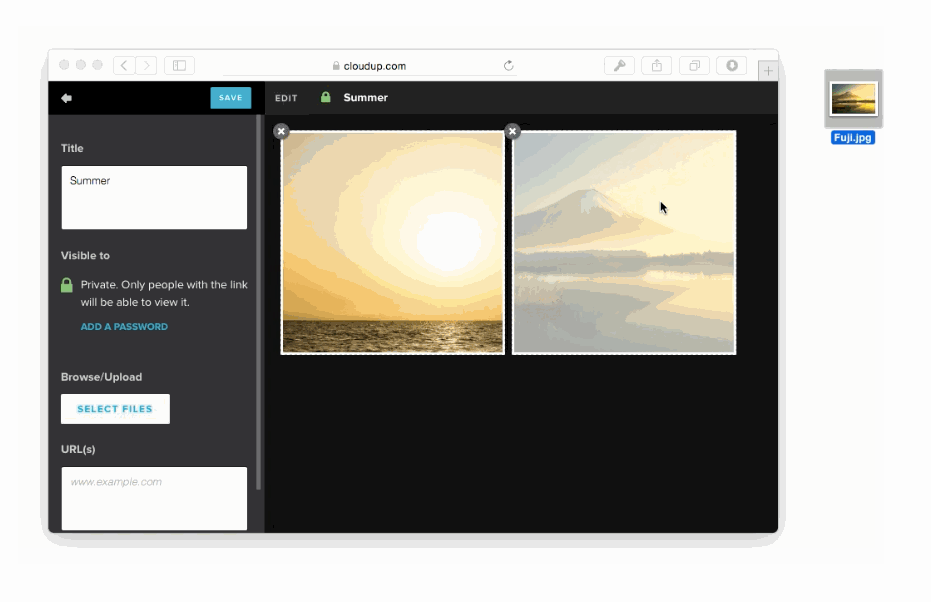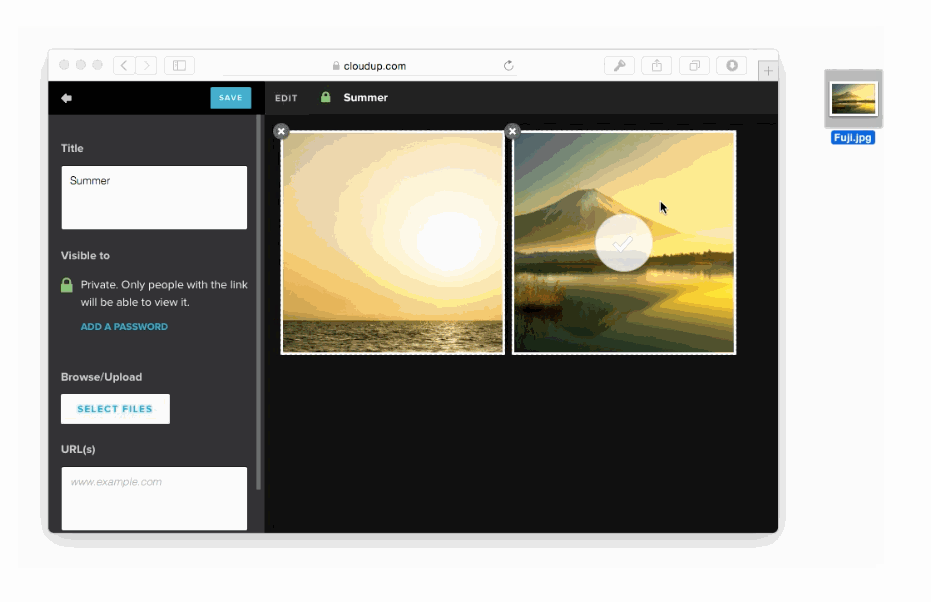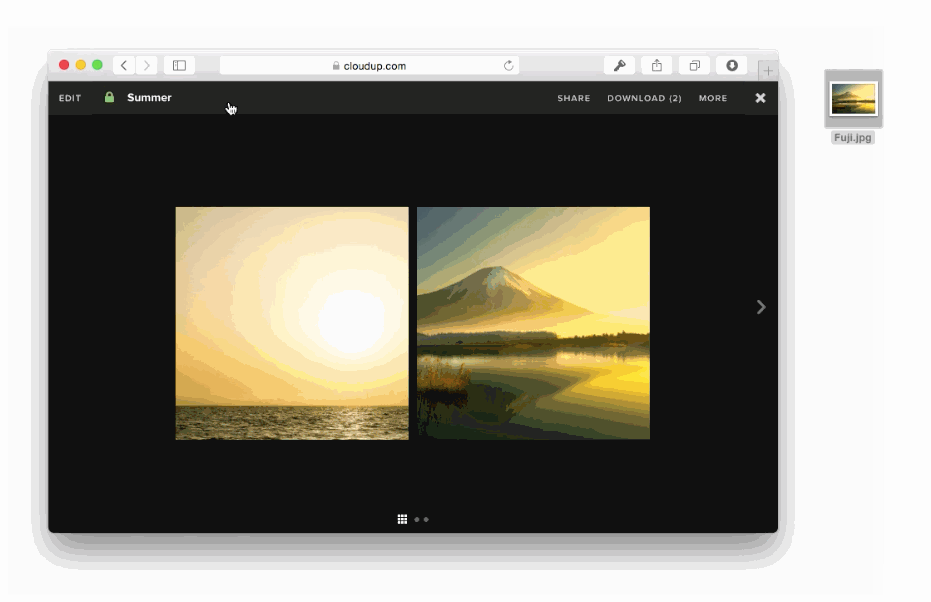
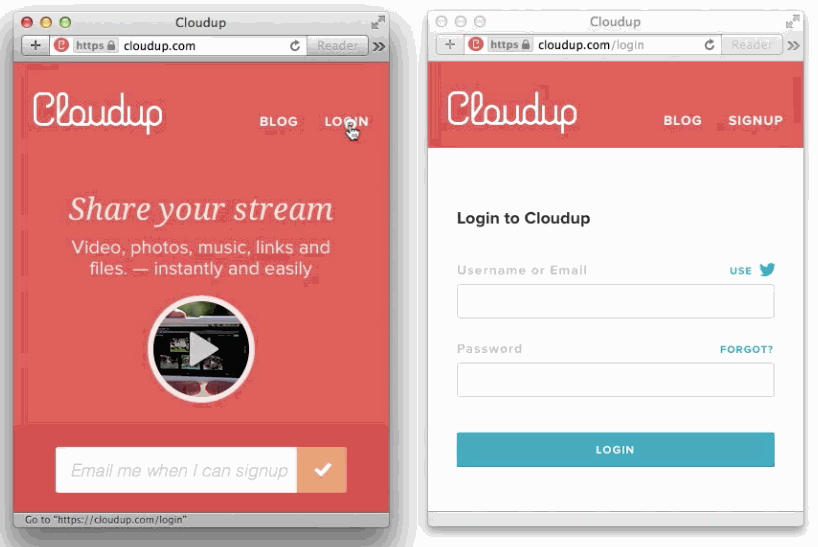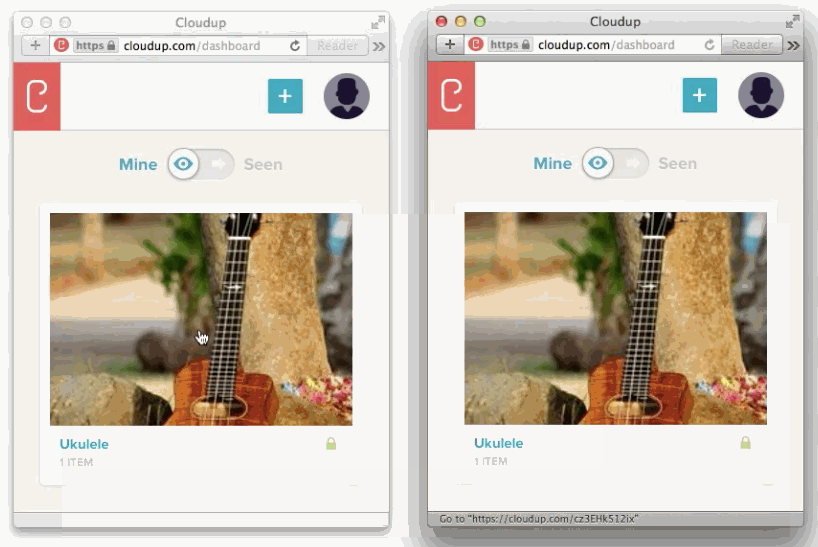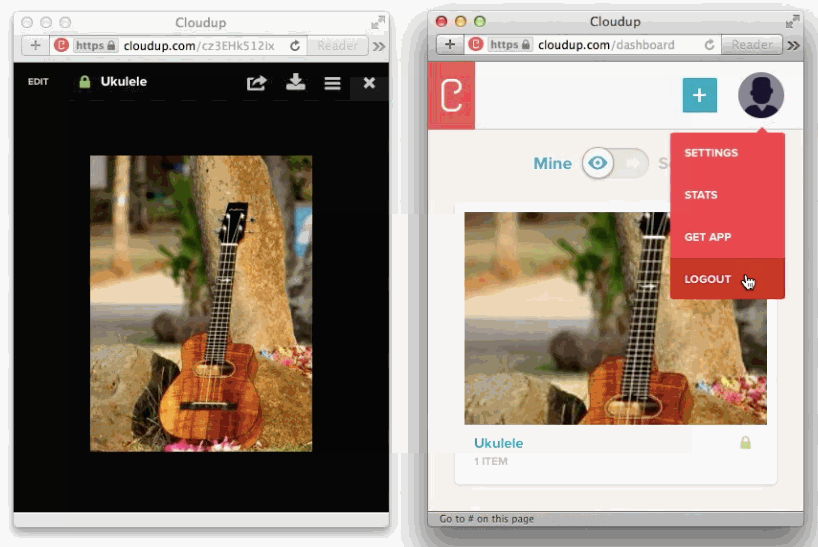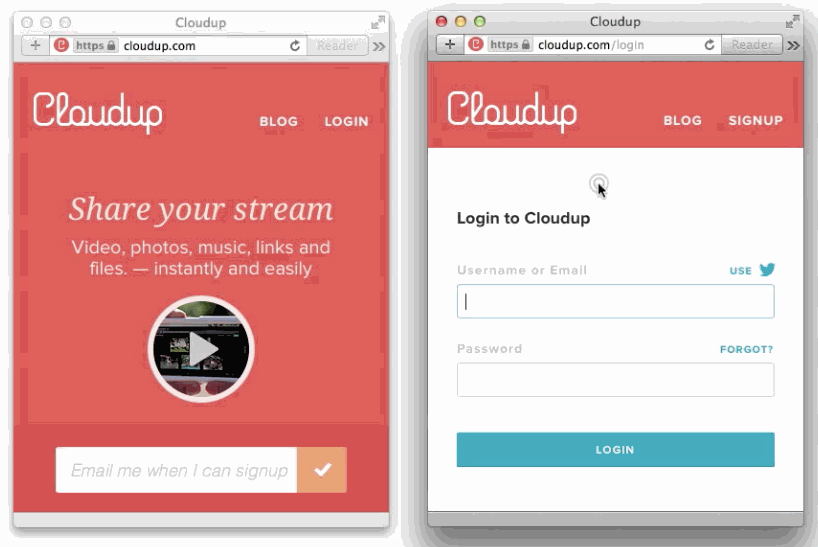
JavaScriptによって入力フォームとクリックとデータ送信が強化される例があります、ファイル入力です。
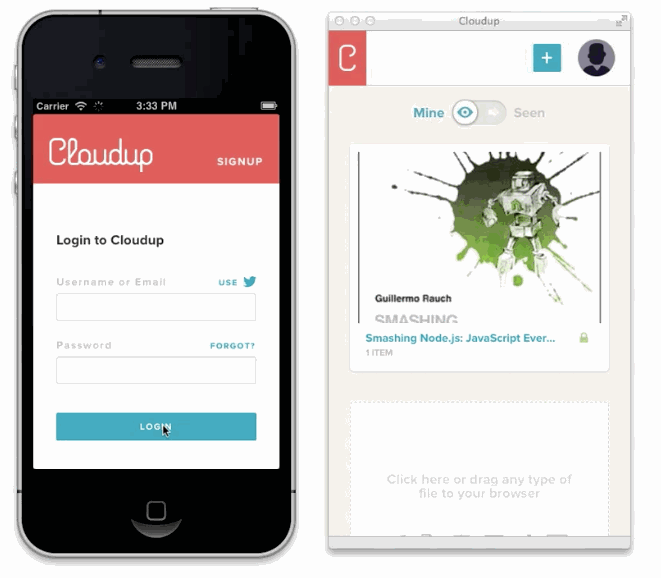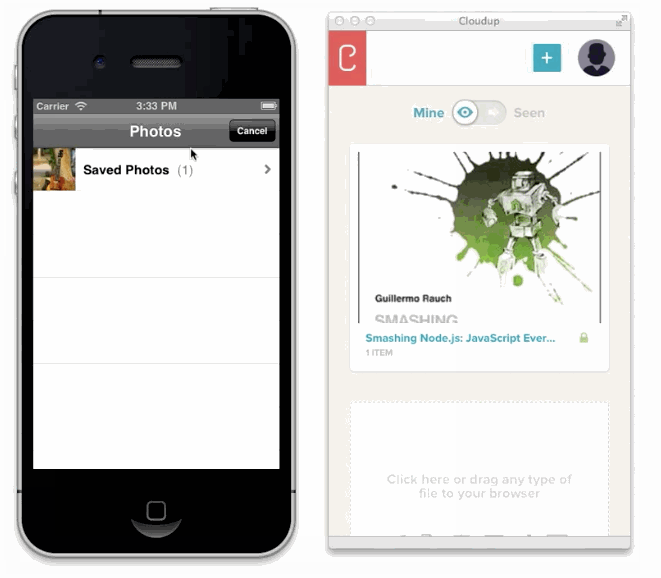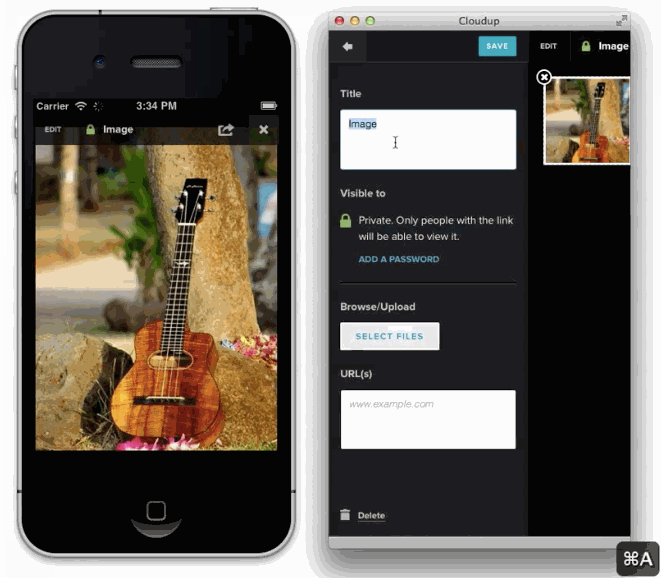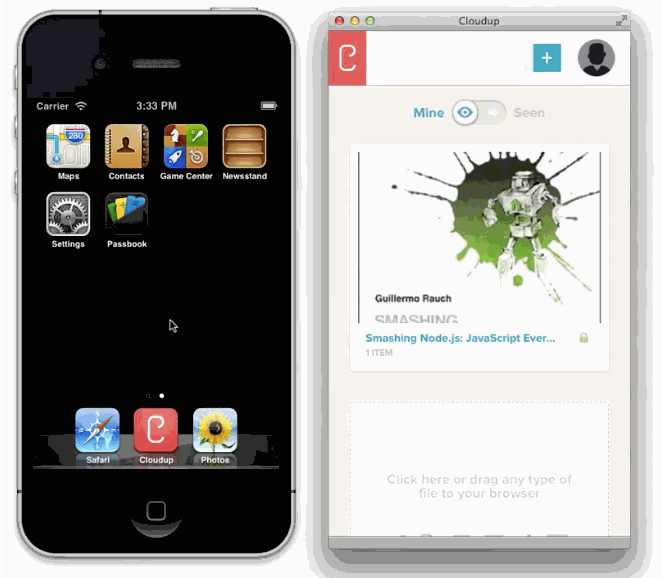
様々な方法でユーザーのアップロードを処理することが可能です。ドラッグアンドドロップやcopy & paste、ファイルピッカーといった方法で処理することが可能です。新しいHTML5 APIに感謝しなくてはいけません。私達はまるでアップロードされたかのようにコンテントを表示することができます。この例はCloudupで画像アップロードをしている最中の動きです。thumbnail画像が生成され、即座にレンダリングされていることに注目してください。
これまでの例において、私達は感覚的にスピードが上がったかのように見せることができます。ありがたいことに、これが良いアイデアだとする沢山の証拠があります。素早く手荷物を扱わなくても、敢えて手荷物受取り所までの距離を増やす事で時間をかけてヒューストン空港でクレームの数を減らした手荷物受取所の例を考えてみてください。
こういう敢えて遅くするようなアイデアのアプリケーションはUI上ではとても深淵な実装をしなければなりません。私は"ロード中を示すインジケータ"とかスピナーがほとんど表示されてはいけないと思っています。生のデータを持ってアプリケーションを遷移する時は特に表示するべきじゃないと思っています、詳しくは次のセクションで触れます。
スピードのごまかしはUXには時に有害になるシチュエーションがあります。支払いフォームやログアウトリンクのような例を考えてみてください。それらに対して楽観的なふるまいをすると、終わっていなかったとしてもユーザーに全てが終わったと通知してしまいます。その結果、ネガティブな体験になってしまう可能性があります。
そういうケースの場合では、スピナーや"ロード中を表すインジケータ"の表示を繰り返すべきでしょう。こういうケースではユーザーはレスポンスが即座だったかどうかはそこまで気にしません。ちゃんと終わってから結果をレンダリングするべきです。Nielsenによる研究結果によれば:
レスポンス時間に関する基本的なアドバイスは MillerやCardらが行っていた研究と13年前から今までほとんど変わっていない。
ユーザーからみて"システムが即座に反応している"と感じるのは大体0.1秒までである。つまり、0.1秒以内であれば、結果を表示するまでに特別なフィードバックは必要ないという事を意味している。
ユーザーがちょっと遅いなと感じる限界は1.0秒までだ、それ以上ではユーザーが遅延したと感じるだろう、そしてデータを直感的に操作する間隔は失われてしまう。
ダイアログが表示されても集中していられるのは10秒までだ、それより長い遅延だと、終わるのを待つよりもユーザーは他のタスクを実行したいと思ってしまうだろう。
PJAXやTurboLinksといったような技術は不幸なことにこのセクションで記述された"あえて遅延させるような技術"を使う機会は失われてしまいます。クライアントサイドのコードはサーバーが起きている全てのラウンドトリップが終わるまで、ウェブページの中で最終的にどんな表示がされるのかは "知らない" と思ってください。
3. データ変更に反応しよう
tl;DR: サーバーのデータが変更された時、リクエストが無くてもクライアントはその変更を知る事ができるでしょう。これは手動でF5を押したり更新したりする事からユーザーを開放するためのパフォーマンス改善です。新しい変更というのは(再)接続管理や状態変更も含みます。
第三の原則はソースや1台以上のデータベースサーバーの中でデータが変更された時のUIの反応についての話です。
ユーザーがページを更新する、AJAXで操作するまで静的なままのHTMLのスナップショットを提供する事は廃れてきています。
UIは自分で勝手に更新されているべきでしょう。
データの要素の数が無制限に増加するようなサイトでは自分自身で更新する事は特に重要です。時計、電話、タブレット、ウェアラブルデバイスは自分自身で更新される事を元に設計されています。
FacebookにPCを通してデータが入力された時に入力とほぼ同時にFacebookはニュースフィードがあるかどうかを確認します。静的にデータを表示することは最適ではありませんでしたが、人々が一日一回自分のプロフィールを更新した場合には意味があるでしょう。
写真をアップロードし、アップロードしたら即座に友達からイイねしてもらったり、コメントを受け取る事ができる場所で生活しています。ユーザー同士がアプリケーションを同時に利用している事を知るためにリアルタイムフィードバックが必要になってきています。
マルチユーザーアプリケーションでしかリアルタイムフィードバックはメリットが薄いと推測するのは間違っているかもしれません。私がユーザーに反対してでもconcurrent data pointsについて話をしたいと思っている理由です。あなたのスマホで写真をラップトップにもシェアするという共通のシナリオで考えてみましょう。
ユーザーに見せる全てのデータをリアクティブとして考えるとわかりやすい。セッションやログイン状態の同期はこの原則を適用する例の一つになるでしょう。もしあなたのアプリケーションのユーザがたくさんのタブを同期的に開いてたとしたら、一つのアプリでログアウトしたら全てのタブに対してページを無効化するほうが良いでしょう。プライバシーとセキュリティを向上させる事につながります、特にたくさんのユーザーが同じデバイスにアクセスするようなシチュエーションで効果を発揮します。
一度、スクリーン上の情報が自動的に更新される事が期待されていました、これからは新しいニーズとして state reconciliation(状態の折り合い)を入れるか検討することが重要になってきています。
アトミックなデータ変更処理を受け付けた時、アプリケーションは適切に更新できるのかどうかを忘れて、勝手に更新するというのは簡単です。でももしもネットワークに未接続な状態で長い期間経過した後だったらどうなるでしょう。ラップトップを一回閉じて、何日か経ったあとで再度開いたというシナリオを想定してみましょう。そのときあなたのアプリケーションは何がどうなっているでしょうか?
時間内にバラバラの状態から折り合いをつける能力は私達の最初の原則にも当てはまります。もしあなたが初期ページロードにデータを送信する方を選ぶのであれば、オンラインになってからクライアントスクリプトがロードされるまでの時間を考慮しなくてはいけません。その時間は本質的に接続していない時間と同じものと見なす必要があります。
4. サーバーとのデータ交換をコントロールする
tl;DR:
サーバーとのデータ交換は今では微調整することができるようになってきています。エラーの発生を確認し、ユーザーの操作を再実行させ、バックグラウンドでデータを同期し、オフラインでキャッシュを維持しましょう。
WWWが考えられ始めた時、クライアントとサーバー間でデータを交換する方法はかなり制限されていました。
- リンクをクリックする事で新しいページを
GETし、レンダリングする POSTやGETをformから送信して新しいページをレンダリングする- 画像またはオブジェクトを非同期に
GETして埋め込み、レンダリングする
このモデルの単純さは魅力的であり、データがどうやって送信されて、受信されるのかを理解しやすく、かなり学習しやすいといえるでしょう。
最も大きな制限は第二の点(formからGETやPOSTでデータを取ってくる点)にありました。新しいページをロードせずにデータを送信する事はできませんでした。パフォーマンスに注目すると最善とはいえませんでした。しかもformからPOSTで送信した場合に戻るボタンを壊すことができてしまいます。
アプリケーションプラットフォームとしてのウェブはJavaScriptなしでは考えられません。AJAXはこういったユーザーが情報の送信する際のUXに関する障害を超えてきました。
今ではたくさんのAPIがあります。XMLHttpRequest, WebSocket, EventSourceといったAPIはデータの流れに対して、きめ細やかなコントロールを提供してくれます。ユーザーがフォームに入力したデータを送るという機能に加えてUXを改善するための機会をいくつも持っているわけです。
特に前の原則に適している機能は接続状態を表示する機能です。もしデータが自動的に更新される事を予測して準備するならユーザーに切断されたことや再接続中の状態を通知するべきでしょう。
切断を検知すれば、メモリやlocalStorageのような場所にデータを保存して後で送信するということができるようになります。これはJavaScriptのウェブアプリケーションがバックグラウンドで動作できるようにするServiceWorkerの導入を踏まえた上でとても重要なものになります。あなたのアプリケーションがオープンじゃなかったら、バックグラウンドでユーザーデータを同期しようとすることもできます。
データを送るときやユーザーの代わりにリトライする時はタイムアウトやエラーを考慮しましょう。接続が再確立したらデータを再送するように検討しましょう。永続的に失敗する場合、ユーザーに連絡しましょう。
明らかなエラーは注意深く扱われるべきです。例えば予期せず403エラーが発生している場合、ユーザーのセッションが無効になっている事を意味します。そういった場合、処理を継続させるためにログインスクリーンを見せることでユーザーにセッションが切れている事を理解させた方が良いでしょう。
ユーザーが不注意にデータフローを止めてしまわないか確認することも重要です。これは2つの状況下で発生する可能性があります。一つはブラウザやタブをうっかり閉じちゃうこと、これは閉じられる前に beforeunload ハンドラ関数で防ぐようにできます。
もう一つはページ遷移が起きてしまうことです。これは発生前にページ遷移を捉えることができます。例えばリンクがクリックされたら新しいページとしてロードさせるといった形です。新しいタブとして表示するだけじゃなく、自身のモーダルで表示させることも可能です。
5. historyを壊すべきじゃない、historyを拡張しよう
tl;DR: URLを管理するブラウザとhistoryがなければ、新たなチャレンジは生まれない。無限スクロール等の技術でhistoryを壊していないか確認しよう。高速なフィードバックのためのキャッシュを常にキープしよう。
フォーム送信やハイパーリンクのみのウェブアプリケーションの設計をするならブラウザの機能にある進む、戻るボタンを使うだけで終わるでしょう。
典型的な"無限ページネーションシナリオ"を例として考えてみましょう。JavaScriptでクリック/スクロールイベントを捕捉し、データやHTMLをリクエストし、それをページにインジェクションするという一連の動作を含めて実装するのが典型的な方法です。history.pushStateやreplaceStateを使うのはoptionalなステップですが、不幸なことにそんなに多くの情報をhistoryに入れることはできません。
これこそが私が"壊す"とうい言葉を使った理由です。ウェブが初期に提案したよりシンプルなモデルには、この将来像は描かれていませんでした。全ての状態遷移がURLの変更に依存することになるとは思われていなかったのです。
これは逆に言うと、historyを改善する新しい機会が生まれたとも言えます。私達開発者がJavaScriptでhistoryをコントロールできるようになったのです。
Daniel PipiusがFast Backと名づけた記事から引用すると:
"戻る"のは素早く行われるべきだ。ユーザーは"戻る"事によってデータが変更されるような事は期待していない。
これはブラウザの戻るボタンをアプリケーションレベルの普通のボタンとして考えるのと同じことです。これには2つめの原則 (ユーザー入力に迅速に対応しよう)と同じ原則が当てはまります。前のページをどうやってキャッシュするかを決め、即座にレンダリングするのがキーになります。原則3のデータ変更に反応しようにも当てはまります。ユーザーの新しいデータ変更があったら通知し、そのページに反映する必要があります。
開発者がcache behaviorを制御しない、いくつかのケースが存在します。例えば、ページをレンダリングした後、3rdパーティ製のウェブサイトに行き、ユーザーが戻るボタンをクリックしたとします。アプリケーションはサーバーにあるHTMLを再度レンダリングし、クライアント上でHTMLを変更します。この時、微妙で分かりにくいバグが入ってしまうリスクが有ります:
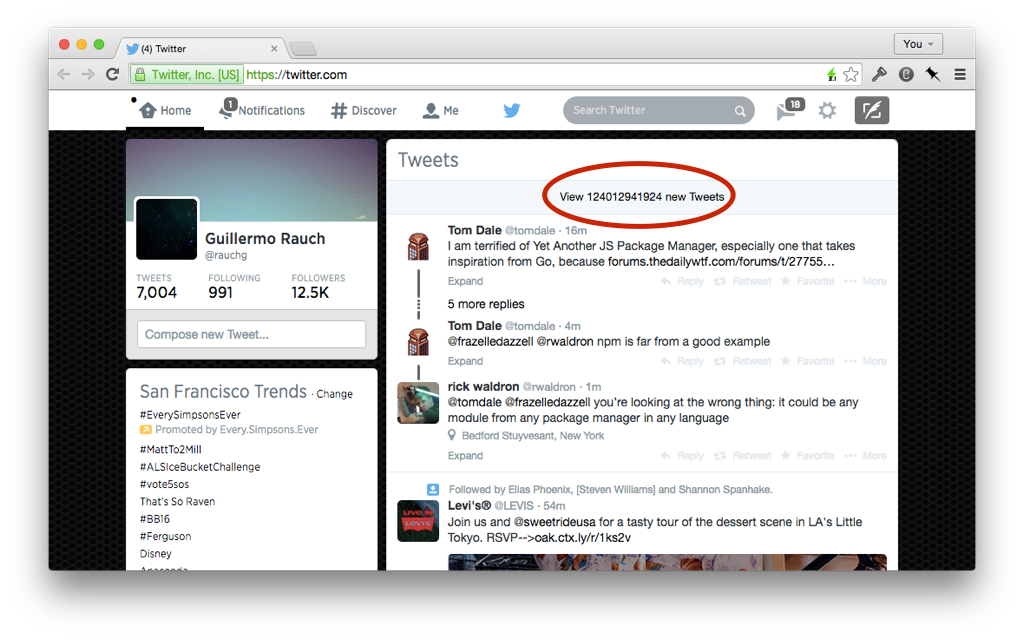
他にもナビゲーションを壊してしまう方法があります。スクロールのメモリを無視するとナビゲーションを壊すことができます。JSに依存しないページや手動でhistory管理するページはほとんどがこの問題にぶつかることはありません。しかし動的なページは常にこの危険があります。私は2つのポピュラーなJavaScript-drivenのニュースフィードを試してみました。TwitterとFacebookです。両方共scrolling amnesia (スクロール位置の喪失)が発生しました。
最終的に、状態変更に気づくことがhistoryをナビゲートする際に適しています。コメントサブツリーの表示をtoggleする例を考えてみましょう。
もしそのページがアプリケーション内のリンクにしたがって再描画されたのであれば、ユーザーは全てのコメントが閉じたまま描画される事を期待するでしょう。状態はvolatileでありかつ、historyスタック内でのエントリと関連付けられるようにしましょう。
6. コードの更新をPushしよう
tl;DR: コードをPushしないでデータだけPushするのは不十分だ。もしデータが自動的に更新されるなら、コードもそうなるべきだろう。APIのエラーを回避してパフォーマンスも改善される。再描画しやすく副作用が少ないステートレスなDOMを使おう。
アプリケーションがコードの変更に反応することは重要です。
最初に、表面に見えてしまうようなエラーは限りなく減らして、信頼性を向上させるべきです。もしもバックエンドのAPIに対して互換性のない変更がある場合、クライアントのコードは更新されなければならないでしょう。さもなければ新しいデータが理解できない可能性があり、互換性のないフォーマットのデータが送られる可能性があります。
コードの変更をPushするもう一つの重要な利点は第三の原則(データの変更に反応しよう)の実装をする時に必要になるという事です。もしUIが自分で更新されるんだとしたら、ユーザーが自分でページ更新を行う理由は殆どありません。
traditionalなウェブサイトのことを思い出してください、ページの更新には2つの意味があります、データの更新とコードの更新です。データをpushする仕組みを準備するだけでコードをpushする仕組みがないのは不十分です、特に単一タブ(単一セッション)は長い期間開かれていることが多いので、コードのpushが必要になります。
サーバーがpushするチャンネルが決まった場所にあるなら、新しいコードが利用可能になった時にクライアントにコードが変わったことを発信させることができます。そういう仕組が存在し無いなら、HTTPリクエストにクライアントコードのversion番号が追加されることになるでしょう。サーバーはそのバージョン番号を最新のバージョンと比較し、リクエストを処理するかどうかを選択し、時にはクライアントに忠告します。
この後、ウェブアプリケーションが適切だと判断したら、ユーザーの代わりにページをリフレッシュするようにします。例えば、ページが見えないとかフォームに何も入力できないという事態にならないようにします。
ホットコードリロードするというより優れたアプローチがあります。これは全ページのリフレッシュをする必要がありません。その代わり、実行中のコードをスワップさせてモジュールをロードし、再実行させるという機能が必要になります。
多くのコードが存在している状況では、明らかにホットコードリロードは難しくなるでしょう。アーキテクチャの種類ごとに議論する余地があります。振る舞い(code)から綺麗にデータ(状態)が切り離されているアーキテクチャである必要があります。そのように分離されたアーキテクチャはパッチを沢山当てた時(メンテナンスする時)に効果的になるでしょう。
アプリケーション内でのモジュールの例を考えてみましょう。そのアプリケーションはsocket.ioのようなイベントでやりとりする口が用意されているとします。イベントが受信された時、コンポーネントの新しい状態が導入され、DOMにレンダリングされるでしょう。その後、前の状態から新しい状態にDOMがマークアップされ異なるDOMが生成されます。これにより、コンポーネントの振る舞いを変更します。
ベースとなるモジュールごとにコードを更新することができるのが理想的なシナリオと言えるでしょう。もしコンポーネントのコードが変更され、更新されるようなタイミングで、例えばsocket接続から再起動するような事になると、意味がありません。
しかし、そうなると次のチェレンジとして、やっかいな副作用なしでモジュールが再評価されるようにできるようにしなければいけません。Reactによって提案されているようなアーキテクチャはこのチャレンジが特にやりやすくなるでしょう。もしコンポーネントのコードが更新されたら、ロジックは再実行され、DOMが効率的に更新されるようになるでしょう。Dan Abramovによるコンセプトの追求はここで見ることができます。
本質的には、"あるDOMにだけ"レンダリングする、もしくは描画するというアイデアはホットコードリロードをかなりやりやすくしてくれます。もしDOM内で状態が維持されていたら、もしくはアプリケーションによって手動でセットされたイベントリスナーがあったら、コードを更新することはより複雑なタスクになるでしょう。
7. 振る舞いを予測しよう
tl;DR: レイテンシーの壁を超えよう。
リッチなJavaScriptアプリケーションはユーザー入力を予測するという仕組みを持っています。
こういうリッチなアプリケーションはユーザーの操作が成立するまえに、前もってサーバーからデータをリクエストするというアイデアを共通して持っています。ハイパーリンクの上にマウスがホバーしたらデータをフェッチし、クリックされた時には既にデータがあるという状態はわかり易い例といえるでしょう。
応用例としては、マウスの動きをモニタし、その軌跡を分析させ、ボタンのようなクリッカブルな要素に対して"衝突"判定させる事です。jQueryの例を見てみましょう:

まとめ
ウェブは情報の送受信のための最も多彩なメディアの一つとして残り続けるでしょう。自身のページにより多くのダイナミズムを追加し続けていくことによって、新しいものを取り入れていく一方で、その歴史的につづいているWebの利点を保ち続けなければなりません。
ハイパーリンクによって相互接続されているページはどんなタイプのアプリケーションに対しても偉大な建造物です。ユーザーが操作するコード、スタイル、マークアップのロードは革新的になっています。この進化はインタラクティブ性を犠牲にすること無く、パフォーマンスを向上させるでしょう。
JavaScriptには最も広く、そして最も自由な既存のプラットフォームのためのUXの可能性を最大限に広げることでしょう。新しく、ユニークなチャンスは至るところで採用されているJavaScriptによって有効になっていくでしょう。