この一年やったこと、継続していること (Rust とか 英語とか)
前回エントリを踏襲し、さらに一年間どんな事をやったか、という話を書こうかなと。
yosuke-furukawa.hatenablog.com
一年間やったことを振り返ると、英語と競技プログラミング、その過程で Rust をやっていました。
競技プログラミング系
LeetCode
この一年間でトータルで解いた問題が806問になりました。これまで JavaScript で解いてたやつを Rust で解き直したりしてたので、解答数はそこまで増えてないのですが、 Rust の勉強と割り切っていたので、目標としては良かったかなと思います。
一年間ずっとやったことで、金バッジをもらいました。
![]()
ただ競技プログラマーとしてなにか成長したかと言うと、前回よりは解けるものの、「解けない問題が解けるようになった」というより「安定して解ける問題が解けるようになった」っていう感じですね。Rust を覚えたりしたものの、解けない問題は相変わらず言語を変えようと解けないですね。 ただ Rust は JS と比較すると既に BinaryHeap の実装があったり、 binary search を実装したものがあったりするので、この関数使っちゃえばおしまい、みたいな利点がありますね。
Rust を覚えるためにやったこと
exercism.io っていうところで問題を50問くらい解きました。
最近Rust書いてるけど、exercismっていうサイトでmain trackをやっと全て完成させた。長かった。
— Yosuke Furukawa (@yosuke_furukawa) February 22, 2021
side trackが残ってるけど、中級程度の競技プログラミングっぽいのはできるようになった。
exercism はメンターからコメントも付くのでモチベーション維持できるおすすめ。 https://t.co/ARwhqV6nKI pic.twitter.com/Tv8DrPylvX
このツイートに書いたとおりなんですが、 exercism は問題を解くだけじゃなくて、解いた後メンターが見てくれます。その上で、性能が遅いとか、もっと match 式を使えとか、こういう関数あるからこれでやれとか教えてくれます。 approve がもらえると嬉しいです。無くても解ければ次の問題にいけます。 main track と sub track があって、 main track は最後に小さい Stack ベースの言語書かされます。めっちゃ楽しい。
後は地道に LeetCode 解いたり、プログラミング Rust を読んだりしていました。第2版がそろそろ出るということなので、買い直そうと思います。
Advent Of Code 2021
今年も完走しました。前回エントリの通りなので詳細はそちらで。
yosuke-furukawa.hatenablog.com
英語
今年は DMM 英会話と途中から ELSA Speak に手を出してやり始めました。
DMM 英会話
20000分以上受けたので、マスターレベルになりました。

この一個上にレジェンドレベルというのがあるのですが、 30000 分以上受けないといけないです。一旦そこまで目指してやってみようかなーと思っています。レジェンド以上は今のところ無いみたいですね。 英会話は勉強って言うより楽しく話せる機会としてやっていて、特にニュースを読んで議論するのが楽しいですね。先日はサービス残業を当たり前のようにする人を「Presenteeism」と呼ぶらしいのですが、 Presenteeism の人は日本に多いのか、クリエイターの人はなぜ Presenteeism になりやすいのかについて議論しました。また他の日にはアフガニスタン情勢がアメリカ軍が引き上げたことで変わったことについて議論しました。だいぶセンシティブな話題を議論しています。
ELSA Speak
ELSA Speak は発音矯正アプリなのですが、これまた楽しくてやってます。自分で実際に発音して、それがネイティブにどれだけ近いかどうかで点数を測ってくれます。アメリカ英語の発音とイギリス英語の発音もその他の英語の発音にも対応していて、それらのどれに近いかを認識して、近い方で点数を出してくれます。
ネイティブに近ければ近いほど点数が高いのですが、今の所発音は 95% まで来ました。
95%記念
— Yosuke Furukawa (@yosuke_furukawa) December 8, 2021
Elsa is an app that speaks English with me. Try it with me. https://t.co/YYPqAkjlvh #ELSASpeak pic.twitter.com/Nju97Dt8yn
ただ実は自分がネイティブの発音に近いからこの点数というわけではないんです。何度も何度も繰り返して良い点数が出るまでやってるので、この点数なのです。とにかく反復して何度も発音して、コツを掴んでもう一回やって、、、というのの繰り返しですね。発音した後88%以上だと合格みたいな独自ルールでやっていると割と高くなりました。 やり続けているおかげか、まだまだ発音も完璧ではないですが、少しずつネイティブっぽい発音に近づけています。
読書
今年は途中で割と読書も心がけてました。というのも DMM 英会話で雑談するにしても知識がある程度共有されていないと有効な話し合いにならないのと、家事の合間に軽くサクッとインプットできる趣味を考えていたら読書が最強だったという事、後は最近やることが増えてきて、自分の知識が単純に足りないなと思ったことがきっかけでした(特に経営面)。
大体毎月1, 2冊は読んでたと思います。
Web配信の技術 読了。
— Yosuke Furukawa (@yosuke_furukawa) June 3, 2021
CDNの話が大部分でその部分もかなり面白かったけど、最初のところでかなり詳細にCacheの制御をどうするかをHTTP headerの解説含めてしていて勉強になった。後半の如何にCDNトラブルを防ぐかといった話も面白かった。https://t.co/79RPw7frnB
両利きの経営、読了。
— Yosuke Furukawa (@yosuke_furukawa) July 28, 2021
企業が持続的に発展していくため、またいわゆる"イノベーションのジレンマ"に陥らないようにするためには"両利き"でなければいけない。つまり既存事業をうまく運用しつつ新規事業を達成する必要がある。そのケーススタディがたくさん掲載されている。https://t.co/pcVeUTcuQd
グリーン・ジャイアント読了。
— Yosuke Furukawa (@yosuke_furukawa) November 28, 2021
日本と世界のエネルギー政策についての差や現在の状況がわかりやすく解説されてて非常に勉強になった。
グリーン・ジャイアント 脱炭素ビジネスが世界経済を動かす (文春新書) https://t.co/srHLjaZ5pS
ビジョナリーカンパニー ZERO読了。
— Yosuke Furukawa (@yosuke_furukawa) December 28, 2021
めっちゃ面白かった。
「最高のビジョンを実現するには最高の人材が必要」
「自らの成功をお金で測ると必ず敗者になる」
など、名言多い。
"ビジョナリー・カンパニーZERO ゼロから事業を生み出し、偉大で永続的な企業になる"https://t.co/0ItLbx1mkF
こんな感じで幅広く読んでました。ただもう少し思ったのはちゃんと読んだ後、 Twitter で放流するだけじゃなくて、ブログとかでまとめておかないと忘れてしまうなと思ったので、ちょっとどっかでまとめようかなと思います。
数学
数学のインプットはむしろ減ってしまったかもしれません。というのも、朝に英語やる事で数学を解く時間が減ってしまったことが原因ですね。まぁこの辺はなにか別なことにリソースを割いたら、別なことが犠牲になっているだけなので、どっかで濃度を調整すればまたやれるようになるかなと思います。一応毎日購読してる数学の Youtuber のチャンネルは見れるときに見ています。
さて次どうしよう
去年やるという目標を立てていた Rust の勉強はできたのですが、 Rust で何か面白いアプリを作ったり、ライブラリを作っているわけではないので、もうちょい実用的なものを作ってみようかなと思います。フロントエンドエンジニアにも Rust が必要になるケースが増えてきており、なんかその辺りでできることないかなーと思っています。英語に関しては一旦スラスラとは話せないものの、ある程度まで話せるようになってきているので、後は繰り返しなのかなーと思ってますが、実は文法とかあやふやだったり、語彙ももう少し身に着けないとなと思っています。話すこと、聞くことはできても、読むこと書くことが苦手になりつつあるので、もう少しちゃんとできるようになりたいですね。
読書や数学と言った新しいインプットも継続的に行いつつ、来年はアウトプット方面をもう少し頑張りたいです。
Advent Of Code 2021 完答した
Advent Of Code 2021 に参加して、今年も毎日コード書ききりました。。。大変だった。。。
今年も楽しかった。一個だけできなかったけど。。。
— Yosuke Furukawa (@yosuke_furukawa) December 26, 2021
I just completed all 25 days of Advent of Code 2021! https://t.co/L3evwKeuG2 #AdventOfCode
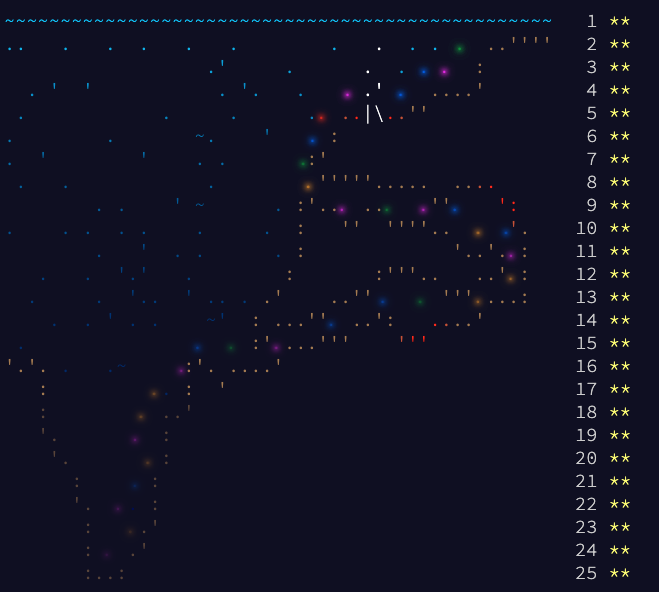
Advent Of Code とは
Advent Calendar 形式で一日ずつ問題が出てくるので、それを毎日ひたすら25日まで解かせるというやつです。去年もやったんですけど、ただただ大変で、後半は問題出てきたとしても気持ちが折れかけたりします。ただ解けると楽しいんで、やってしまうという中毒性のある遊びですね。
ちなみに去年のやつです。
yosuke-furukawa.hatenablog.com
今年こそは全問何も見ずにちゃんと自分で考えて解くぞと思ってたんですけど、 day23 で気持ちが折れてしまって、解答を見てしまいました。自分との勝負ではあるものの、年末くらいはゆっくりしたいっていう気持ちに勝てませんでした。。。
今回は Rust で参戦
去年は JS だったんですけど、 Rust 勉強するかーって言って一年間 Rust で LeetCode やったり、 exercism で勉強したんで、集大成として Rust で参戦しました。
まだまだ Rust っぽい書き方ができるようになったとは言えないんですが、普通にコードは書けるようになりました。もうちょい実用的な処理を書いてみたいですね。来年はなんかライブラリとかアプリとか作ってみようかな。
思い出に残っている問題
思い出に残った問題を上げるなら以下の通り。ネタバレがあるので、これから自分で解きたい人は見ないでください。
ビンゴゲームをイカと一緒に解くっていう問題。数字が記載されているので交互にビンゴを完成させていって、勝ったらスコアが加算されるので、総スコアを答えよ、という問題。意味不明なお題で面白かったです。イカゲームと掛けたのかなこれは。。。
Day 13: Transparent Origami
折り紙を一定の座標軸で折り曲げていって、最後に出てきた画像に書いてあるアルファベットを答えさせる問題。これまで見たこと無い感じの面白い問題でしたね。
Day 14: Extended Polymerization
拡張された重合反応?っていう日本語訳になるかもだけど、要は化学元素記号みたいなものが反応されることで別な記号に生まれ変わる、その記号が反応し合うことで最終的にどういう文字列になるかという問題。
バカ正直に最初解いてて、途中から短く解けるアイデアを使ったら一発で解けてよかった。
Day 15: Chiton
よくあるスタートからエンドまでの迷路を一番効率よく辿れるパスを当てるっていう問題。 A* みたいなアルゴリズムで解こうか迷ったけど、結局 BinaryHeap を使った優先度キューみたいなもので解いてしまった。
この辺りまでは楽しいんですよね。前半の15日目くらいまでは。。。(ずっと前半やってたい)。
Day 16: Packet Decoder
なんでかよくわからないけど、エルフが出てきてバイナリーで話し始めたという所から独自のバイナリをデコードさせるっていう問題。とにかく仕様が複雑で、パケットの中にもサブパケットと呼ばれる入れ子構造になったパケットをデコードさせるので、再帰呼び出しで解く必要があり、また複雑なことにいくつかパケットのタイプが分かれてて、特別な処理が必要なパケットもあったりします。最後に leading zero で zero 値埋めがされているところとかも現実っぽい感じになっていて、とにかく「めんどくさい」問題でした。後半戦にはいったな、っていうことを思わせる問題でしたね。
Day 19: Beacon Scanner
三次元座標上にあるビーコンがあり、センサーがそれを検知するんですが、センサーの向きは教えてもらえず、ビーコンが見つかった三次元座標は渡されるものの、どの向きで発見した座標なのかはわからない、という問題です。書いただけじゃ何言ってるかわからないですね。三次元座標の原点の向きがバラバラになっているところで、すべてのセンサーが発見したビーコンの数を当てよという問題。頭の中でずっと座標をぐるぐる回転させてて、それでも全くどういうパターンが有るのかは分からず、色々座標を書いてパターンを見つけ、、、というほんと大変な問題だった。。。
Day 22: Reactor Reboot
原子炉を再起動させるために特定のパターンでボタンを押さないといけないが、こちらも三次元平面上にあるボタンをオン・オフして最後にオンになっているボタンの数を数えるという問題。書いただけじゃよくわからない問題パート2ですね。問題自体はめちゃくちゃ大変というわけではないものの、アルゴリズム力が求められるような問題でした。
Day 23: Amphipod
ここで一回力が尽きます。 Day 23 も問題自体はシンプルです。いくつかの微生物がいて、そいつらがパズルのように動くので、動いたコストの最小値を求めよ、という問題です。パズルを解ければ OK なんですが、もう day 22 で一回力尽きてたので、やる気がどうしても起きず、一回答えを見た上で解きました。気が向いたら自分でも解いてみます。
Day 24: Arithmetic Logic Unit
僕一番好きなやつですね。 Arithmetic Logic Unit というアセンブリ言語のような言語があるので、仕様どおりに計算を進めた上で、 4 つの processing unit がどのような値になるかをシミュレートするやつです。入力から出力を出すのではなく、出力から入力を推測しろという問題なので、全パターンを試そうとすると 9 ^ 14 の入力パターンを試す必要があり、そのままやると終わらないです。
自分はキャッシュを使って簡単なやり方で解いてしまったのですが、終わった後に色々見たら、 アセンブリ言語の JIT を作った猛者がいたりと、めちゃくちゃクリエイティビティなやり方で解いてる人が居て面白かったです。
https://github.com/cemeyer/advent-of-code-2021/blob/master/day24.rs#L164-L304
まとめ
去年 すぎゃーんに言われて始めた Advent Of Code だったけど、今年も継続してやることができました。しかも去年やるって言ってた Rust を学んだ上でそれで挑戦し、解くことができたのは、嬉しかったです。
来年は全部ちゃんと解けるようになりたいなーと思いつつも、健康や家族を優先にし、その中でやれる範囲でやれるようにしたいと思います。
Node.js の assert の小話
Node.js Advent Calendar の4日目の記事 です。
Node.js の assert は結構歴史が深いです。あまり直接使ってる人は少ないかもしれません。使うとしたら test で使ったりするケースでしょうか。 それも最近は jest に生えてる便利ライブラリを使うほうが多いのかもしれないですね。 unassert なんかで開発中に埋め込んでいるケースもあるかもしれません。このようにたまに使うこともあると思うので、覚えておくと良いでしょう。
assert には 4 年ほど前から strict assertion mode というのが追加されています。
今日はそんな小話を。
require("assert") は直接使ってはいけなかった。
もう昔の話ですが、 require("assert") が deprecated になっていた時期がありました。知らない人も多いんじゃないかと思います。
なんで deprecated だったかというと、 一部の関数が意図しない動きをしていたからです。
const assert = require("assert"); assert.deepEqual(/a/gi, new Date()); // 例外が上がらない (v9.0 時点での話。v10.0 以降だと例外が上がる) assert.deepEqual('+00000000', false); // 例外が上がらない (最新でも例外が上がらない)
deepEqual は中身のプロパティが Loosely に同じかどうかを見ているだけなので、 == とかと同じく、 厳密な型チェックの同一性を確認しない働きをします。
この他にも assert.fail がよくわからない動きをします。
assert.fail("should not be reached") // Throw AssertionError should not be reached
assert.fail は fail するという関数です。本来的な使い方で言うと、 test でここに来ちゃったら fail ですよっていうときにメッセージを出す目的で使います。
ただ2つの引数を渡すと第1引数を actual 、第2引数をexpected として Error にメッセージを詰めて throw してくれます(そんな機能いらない)。
assert.fail("a", "b") // Throw AssertionError a != b assert.fail("a", "a") // Throw AssertionError a != a
ちなみに assert.fail に引数を2つ以上渡すことは 今でも deprecated になっています。
そんなこんなで、いくつかの関数が意図しない動きをするので昔は deprecated でした。assert モジュールを使うことは 今は deprecated ではありません。
strict method が出てくる。
この状況を改善するべく、 strictEqual と deepStrictEqual というメソッドが出てきます。これは前述した型が一致しているかまで見る assert method になっています。普通にこっちを使うほうが良いです。
assert.deepEqual([[[1, 2, 3]], 4, 5], [[[1, 2, '3']], 4, 5]); // OK 3 と '3' は == では一致するため assert.deepStrictEqual([[[1, 2, 3]], 4, 5], [[[1, 2, '3']], 4, 5]); // Throw Assert Error
ただ細かい注意点としては、 deepStrictEqual は厳密等価演算子である === と同じではありません。
どちらかというと、 同値かどうかを表しています。 ECMAScript 的に言うと Same Value かどうかなので、 Object.is() の deep 比較と似ています。
そのため、 NaN 同士の比較も true になります。
assert.deepStrictEqual(NaN, NaN); // OK NaN と NaN は === で違うが、 Object.is() では true のため。 assert.deepStrictEqual(+0, -0); // Throw Assert Error +0 と -0 は Object.is() では false のため。
(それじゃあ deepSameValue のが良いのではないか?と思って、一応 issue で提案したんですが、まぁ微妙な議論になりそうだったので、引き下がりました。)
strict assertion mode が出てくる。
こんな感じで deepStrictEqual が出てきてメデタシメデタシではあったのですが、 deepStrictEqual というメソッドが微妙に長くて使いにくいです。 あと、 strictDeepEqual だっけ? deepStrictEqual だっけ?ってどっちがどっちかわからなくなったりします。そもそも deepEqual 微妙だよねっていう話もあり、最近では "assert/strict" の方を使って、 deepEqual でも deepStrictEqual と同じ動きになるように変更されています。
import assert from "node:assert/strict"; assert.deepEqual([[[1, 2, 3]], 4, 5], [[[1, 2, '3']], 4, 5]); + actual - expected ... Lines skipped [ [ [ 1, 2, + 3 - '3' ] ... 4, 5 ] at file:///private/tmp/test/strict.mjs:3:8 at ModuleJob.run (node:internal/modules/esm/module_job:195:25) at async Promise.all (index 0) at async ESMLoader.import (node:internal/modules/esm/loader:337:24) at async loadESM (node:internal/process/esm_loader:88:5) at async handleMainPromise (node:internal/modules/run_main:65:12) { generatedMessage: true, code: 'ERR_ASSERTION', actual: [ [ [ 1, 2, 3 ] ], 4, 5 ], expected: [ [ [ 1, 2, '3' ] ], 4, 5 ], operator: 'deepStrictEqual' }
まぁ正直どっち使っても良いんですが、 assert/strict にして deepEqual つかうか、 assert にして deepStrictEqual 使うかという選択肢が増えています。
まとめ
assert に strict assertion mode ができたよっていう話でした。
Node.js コアモジュールの import/require には `node` schemeがつけられる
Node.js アドベントカレンダーの 3 日目の記事です。空きを埋める形で始めました。
CodeGrid でも書かせていただきましたが、 Node.js で ES Module / CommonJS を使ってコアライブラリのロードをする際、 node から始まる scheme を付けることが可能になっています。
// ESM import fs from "node:fs/promises";
// CJS const http = require("node:http");
これにはいくつかのメリットがあります。基本的につけておくことが望ましいです。 今回はメリットをいくつか紹介します。まだこれがデファクト・スタンダードになっている訳ではありませんが、これから付けてもらうように推奨していきたいと思います。
メリット1: Node.js コアモジュールであることが明示される
Node.js のコードを始めてみたときに、このモジュールが Node.js コアから提供されているのかそれとも npm から提供されているのかイマイチよく分からなかった経験ありませんか。
querystring というモジュールがコアからも npm から 3rd party library としても提供されているので、昔誤って npm install querystring してしまうこともありました。これをインストールしたとしてもコアモジュールのほうがロードされるので、余計なものが入ってしまうだけではあるのですが、なるべく避けたい事態ですね。
今回からは node:querystring で初めておくことで、コアモジュールからのロードであることが明示されます。意図しないダウンロードも防げるでしょう。
メリット2: Node.js の将来のコアライブラリが既存のライブラリと被ることを避けられる
http2 モジュールを作るときに最初 require("https").http2 のような形で提供するかどうかを議論になったのですが、これはもともと http2 モジュールが取られていたからで、メジャーバージョンアップで提供する際に require("http2") にする形に落ち着きました。
こういうことは将来的にも起き得る可能性があります。つまり、 Node.js コアモジュールとそれ以外との名前が将来的にかぶってしまうと面倒なことになります。 http2 のときはまだそこまで流行っていないライブラリでしたが、今後流行っているライブラリで起きた場合はエコシステムに影響が生まれます。
そういう事も考慮して node scheme を付けておくことで、 3rd party ライブラリとの差別化を最初から図れるメリットがあります。
細かいところ
これ以外にも細かい所としては、 ES Modules は本来 import 文にかけるのは URL を書く仕様になっています。この node: から始まることで URL valid な文字列をちゃんと記述することができるようになります。今の書き方は Node.js 独自の拡張です。(ただこの独自拡張も import maps などの新しい仕様により、仕様側が Node.js 独自拡張もカバーする形になるかもしれませんが)
さらに細かいところ
require 構文の中で node scheme を付けた場合、 require.cache で中身を差し替えるハック は使えなくなります。これを使って色々 Node.js のコアモジュールを差し替えているモジュールがあった場合、うまく動かなくなる可能性があります。 ES Modules の場合は require.cache を使っておらず、そもそも改変はできないようになっています。
// このように書いた所で、 node:http モジュールは変更できない。
require.cache[require.resolve('node:http')] = function() { console.log("http modified") };
まとめ
node scheme はつけていこう。
例外を初めて実装した言語
リクルートアドベントカレンダーの20日目の記事です。
最初にこの疑問を思ったのは、今も忘れない R-ISUCON 2021 というリクルートの社内ISUCONの運営で炎上していた時の話です。 ちなみに R-ISUCON 2021 は劇的な結果で終わっているので、興味のある方は見てみてください。
R-ISUCON 2021 では、 Node.js (TypeScript), Go, Java の3パターンの実装が出てくることが通例になっていまして、今回は Java の実装から Node.js, Go に適用していた時に一緒に実装していたメンバーからの疑問が『例外には色々な議論があるけれど、「例外を初めて実装した言語」ってどういう気持ちで実装したんだろう』という話が挙げられたので、そのネタを持ってきました。
ちなみにここで指している例外というのは、値を return した時の value が既定値以外かどうかでチェックする方法ではなく、専用の機構として例外という考え方を実装したのはどういう言語からで、どのくらいのタイミングからだろうかというのが気になったので調べてみた感じです。 return と if で既定値以外かどうかをチェックする仕組みも例外ハンドリングの一種だと思いますが、そうではなく、専用の仕組みとして例外を実装した言語は何なのかが知りたくなって聞いてみた感じです。
竹迫さんからのコメント:

koichikさんからのコメント:

実際には諸説あったので、いくつか紹介します。ただおそらく一番古いのは LISP であるという事になりそうです。
StackOverFlow からは PL/I 説
StackOverFlow からのコメントでは、 PL/I と CLU が挙げられていました。PL/I が 1964 年頃、 CLU が 1973 年頃に実装されていたものと言うことで、だいぶ昔の話ですね。
PL/I は専用の機構として、 try catch 構文で表すものではなく、 SIGNAL という信号とそれを受け取る ON という専用の命令を持っていて、それを使った形で実装されているみたいです。なんか JavaScript のイベント駆動なエラー処理の方法と全く同じですね。
SIGNAL ERROR; ON ERROR BEGIN; . . END;
実際にはこの辺りに記述があります。
ON-condition An occurrence within a PL/I program of a condition that could cause a program interrupt, such as division by zero. ON条件は PL/I のプログラム内で問題が発生した時にプログラムに割り込む事が可能になる。問題というのは例えば 0 で割った場合などを指す。
という記述がありますね。
例外的な状況に陥った時に割り込み命令のような形でエラーを出し、それによって緊急ハッチのように大域脱出な動きをするのが初期の例外という感じですね。こうなっちゃったらもう潔く死んでしまうという判断をするんでしょうけど、死ぬ前にログを書くなどの処理をしていたのでしょう。
CLU も例外ハンドリングができるようになっていますが、こちらの場合は Java で言うところの検査例外のように例外を補足する時に任意の例外を選んで補足するという when 句を使った書き方が可能になっています。
stack$pop(foo(mystack))
except
when empty:
% handler code
stream$putl(stderr, "popped empty stack")
when foo_ex(i: int)
stream$putl(stderr, "foo exception: " || int$unparse(i))
when bar, baz (*):
% ignore exception results, if any, of these
% bar and baz may have different number and types of exception results
others:
% all other exceptions handled here but results are lost
end
% flow continues here
なんとなく、こちらの方が後発っぽいですが、最近の流れに親しきものを感じますね。
英語版 wikipedia からは LISP 説
Software exception handling developed in Lisp in the 1960s and 1970s. This originated in LISP 1.5 (1962), where exceptions were caught by the ERRSET keyword, which returned NIL in case of an error 1960年代から70年代にかけて、例外処理が開発されてきた。 これはLISP 1.5 (1962年から) が起源であり、 エラーの時に NIL を return する代わりに ERRSET キーワードによって例外をキャッチするものとして登場した。
こちらのほうが正確そうですね。 LISP が 1962 年から ERRSET なる機構を用意し、それが return ではない形で処理するための専用の機構ということです。これにはちゃんと続きがあります。
Error raising was introduced in MacLisp in the late 1960s via the ERR keyword. This was rapidly used not only for error raising, but for non-local control flow, and thus was augmented by two new keywords, CATCH and THROW (MacLisp June 1972), reserving ERRSET and ERR for error handling. エラーを上げることは MacLisp 内に ERR キーワードを使って 1960 年代後半に導入されました。これは急速に利用用途が広がり、 いわゆるエラーを上げるという事だけではなく、ローカルの制御フローにも使われました。これにより2つの新しいキーワードが導入されます。 CATCH と THROW (1972年) をローカルの制御フロー用のものとして使い、 ERRSET と ERR はそのままエラーを上げる用途として残りました。
おお、、、となると、最初は例外(エラー)を上げることと、 ローカル制御フロー用の例外的な状況、 所謂 Java で言う検査例外的なものはそもそも制御構文からして違ったわけですね。
ちなみに PL/I の SIGNAL / ON の構文は所謂エラーにも検査例外にも使われていたようです。ただ英語版 wikipedia には このような使い方をするのは現代では一般的ではない と言われてますね(JavaScript ...) 。
例外が発明された後
LISP が発明したものが MacLisp に専用構文として使われ、その後 C++ がこの機構を try catch throw を使った形で導入します。 C++ は例外処理の中で利用したリソースを解放するという目的でも利用されます。メモリの解放や open したファイルのクローズ等が必要になるため、大域的に脱出して終わりにするのではなく、 catch に入ってから後始末をやることがあります。ちなみに C++ にはデストラクタと呼ばれるオブジェクトの終了時に呼び出すメソッドがあり、 RAII (Resource Acquisition Is Initialization) という考え方も早くから使われていたのでfinally構文がなくてもリソース解放はできていました。また、 Java には finally 句があったり、 try-with-resource 構文があります。
Java は検査例外という堅牢(だけど、割と面倒な)仕組みを作り、例外処理をきちんとハンドリングさせようとしますが、 C# などの Java の影響を受けた言語にはそれが引き継がれませんでした。 Java の検査例外に対する批判は「結局例外処理を強制させようとしても、殆どのプログラマーが無視したり、そのまま投げたりしてるだけ」という話に繋がります。
この後は Go が多値の return で表現しつつ、エラーは panic で表現するなど、原点回帰していく流れをみせており、今日の流れにつながっています。
最後に
ひょんな雑談からこんな話に繋がりました。みなさんもぜひ一度は英語版の例外処理の項目を見ることをおすすめします。ちなみに Vue.js の話や React の話なんかも少しだけ書いてあります。
Node.js や deno に Web Standard な API をなんでも取り入れるのが良いことなのかについて
この記事は Node.js Advent Calendar の 11 日目の記事です。
Web API と Node.js
ES2015 以前の Node.js は Web Standard な API の中で足りないものを自分で補う形で進化を続けてきた。 Callback や Event 主体での非同期処理や Common JS な形でロードできる独自のモジュールの仕組みがその筆頭だと思う。ただ逆に Web Standard な API が流行ると今度はそれに追従していかないといけなくなってきた。 ES2015 以後に流行ったものといえば、 Promise 主体での非同期処理であり、 async-await での処理だと思う。また、 ES Modules の台頭もあり、今日では Node.js でも普通に呼び出すことが可能になった。
今ではどちらも Node.js で普通に使える。エコシステムを壊さないようにした結果、 Node.js の ES Modules が普通に使えるようになるには時間がかかったが、いずれにせよ今は使えている。
TC39 だけが Web Standard なグループではない。 WHATWG や WICG 、 W3C などのグループもそれぞれ存在し、それぞれが Web Standard な API を作っている。これらを後追いで Node.js は使えるようにしてきた。 Event Target API, Text Encode / Decode, WHATWG URL, Web Stream, Web Crypto, AbortController などなど、足りないパーツを補う形で作られている。
deno は最初から Web Standard な API をベースに設計されており、割と Node.js よりも既存ブラウザに存在する機能を積極的に持ってきている方だと言える。後発なだけあって、エコシステムに配慮する必要がない分迅速に対応ができている。
Node.js / deno が Web Standard API に追従する状況は現在でも続いている。ただし、最近は若干やりすぎなのではないかというか、本当に必要なのか?と思うようなものまで入っているし、検討されている気がする。
自分の立場を明確にしておくと、「新しい Web API に追従することは良いことだと思うが、不要な API にまで追従する必要はないし、無理矢理ブラウザと同じ API にする必要もない」という立場だ。
新しい Web API が必要か不要かにはいくつかの観点があると思う。筆者は以下のように観点を感じている。
- 全てのブラウザでコンセンサスが取れていること
- Node.js / deno の利用者が呼び出した時にどうなるのかが既存の API と比較してイメージしやすいこと
- 新しい機能が入ることでセキュリティホールが生まれにくいこと
この観点でいくつか考えてみようと思う。
atob / btoa が Node.js / deno に入った。
atob と btoa は 文字列を encode して base64 にしたり、 decode して元に戻す時に使う、binary から ascii (base64) に変換 (btoa) し、 ascii (base64) から binary に戻せる (atob) という API だ。ブラウザでは昔から実装されている。
ただし、この文字列は名前の通り ascii (base64) にだけしか適用できない。 btoa が binary to ascii (base64) の略語だと知っていれば binary (latin1) な文字列にしか使えないことはわかるが、一方で日本人のように latin1 以外の表現を文字列としてナチュラルに使っているところもあると思う。特に任意の文字列を base64 に変換する API だと誤解して使っていると不用意なバグを埋め込む可能性もある。 encodeURIComponent などで無理矢理日本語を binary (latin1) に変換してから使えば一応使えるが、イディオム的で直感的ではない。
> atob(btoa("こんにちは")) Uncaught: DOMException [InvalidCharacterError]: Invalid character > decodeURIComponent(atob(btoa(encodeURIComponent("こんにちは")))) 'こんにちは'
すでに Node.js にも deno にも実装されている。しかし Node.js は実装した瞬間にこれは使うべきではないと実装者から言われている。
Node.js 16 comes with atob and btoa globals.
— Anna 🏳️⚧️ #blm (@addaleax) April 20, 2021
DO NOT USE THEM.
If you think you want to use them, read up on character encodings until you don’t want to use them anymore.
Node.js には Buffer API があるので、これを使わなくても、base64 に変換するような処理は表現することは可能。
const str = "こんにちは"; const base64 = Buffer.from(str, "utf-8").toString("base64"); console.log(Buffer.from(base64, "base64").toString("utf-8"));
こっちのほうが長いので、一見難しそうに見えるかもしれないが、やっていることは simple で utf-8 から base64 に変換している処理であることは掴みやすい。 btoa のような4文字で表現されているAPIは easy な API ではあるものの、ぱっと見てこれが binary to ascii の略で base64 に変換してくれる API だと調べないで分かる人は少ないのではないかと思う。
上述した観点でいうと、「既存のAPIと比較してイメージしにくい」という点と「知らないで使ってしまった時に不用意なバグを埋め込むのではないか」という点でそもそも Node.js には入れなくても良かった API だと思っている。
じゃあそもそもなんで使ってほしくない API を Node.js が実装したのか、というと、Web Standard API に合わせるというコアチーム全体の合意ともう一つが atob / btoa を polyfill して作られているライブラリの存在、最後に deno が既に実装しているという競合からの後押しの3つの理由で実装しているのではないかと推測している。
自分の立場で言えば入れなくても良かった API だと思っているものの、多少複雑な思いもある。 Buffer が Node.js に詳しい人は分かっていたとしても、ブラウザ側のフロントエンドエンジニアにとっては atob や btoa の方が身近な存在である可能性はある。 Node.js のユーザーがそちらに傾きつつある現状においてはその方が良いという意見もわからなくはない。一方でブラウザの歴史的なレガシー API をそのまま持ってくることが本当に良いことなのかは慎重に検討したほうが良い気がする。 特に簡単(Easy) な API というのは難しい。誰かにとっては簡単でも、誰かにとっては不便なものだからだ。今回の例で言えば、「atob/btoaを知っているブラウザのフロントエンドエンジニアにとっては簡単」だけど、知らないエンジニアにとっては一見わかりにくい Bad Parts 的なものであり、これ以上増えていくことは避けるべきではないかと思っている。
だからこそ、コアチームの中にも矛盾した思いがあり、「新しく実装したけどなるべく使わないでくれ」というメッセージを出している。
File system access API
Web を構成する要素として一番難しいブロックの一つにファイルの取り扱いがある。この API はファイルシステムにアクセスできる API をブラウザに実装しようというものだ。
Node.js はまだ検討中で、実装するようなフェーズに入っていない。とはいえ、アイデアとしては検討はしているようだ。
deno は検討中で、 draft PR は出されている。
この API はブラウザ間のコンセンサスがまだ取れていない。
ブラウザ間のコンセンサスが取れてない状況で実装したとしても変わる可能性は大いに有り得るし、最終的に実装されなかった場合には誰も得しない API になってしまう。 まだマージするフェーズにどちらも入っていないものの、Web Standard API を採用するとしても、ブラウザのコンセンサスはさすがに取られたものにしてほしい。プラットフォーム側がいち早く Web API を実装しなくとも、コミュニティ側が「使いたい」という意見が出てから実装したとしても遅くないように思う。
そもそもファイルを取り扱うという一番サーバサイドでよくありそうな基本的な処理をクライアントとして使われるブラウザの API に任せるのは難しい気がしている。
fetch
Node.js では未だに議論を重ねている fetch のサポートだが、 deno には既に入っている。ただ fetch もよくよく仕様を読むと deno / Node.js には不要なものも多い。特に CORS 周りの同じドメイン以外にリクエストを送る時の仕様は Cross Origin という概念が存在しないサーバーサイドでは形だけ API として設定できるように使われていて、実行しても何も意味がなかったりする。つまり、 mode: "same-origin" など設定できるものの特に無意味でリクエストは送れてしまう。こういう形だけの API はどこまで正確に模倣するべきなのかは議論が分かれるところだと思う。逆に Cross Origin 相当の設計を今から deno / Node.js に取り入れるのも労力の割にリターンが見合わないし、どういうものになるのか想像がつかない。
Cache をどうやって取り扱うのかも fetch 内にオプションとして設定できる。ブラウザであればブラウザの cache storage を使う際のオプションとして使われるが、 サーバーサイドで fetch した時にはもちろん無視される。というより、サーバサイドで統一された cache storage なんてものはないし、あったとしても実装がメモリ内に保存するのか永続化するのか、するんだとしてどうやって expired データを取り扱うのかといった概念をセキュリティに配慮しながら実装するのも不毛な気がしている。
Cookie とかはさらに頭が痛い問題である。ブラウザで幅広く使われているが、サーバサイドに持ってくるべきかどうかに関しては今もってお互い議論中だ。
なので、 fetch はあくまでも表向きのよく使われそうな仕様だけ実装してあり、ブラウザとの 100% compatible なものを目指すことは deno にせよ Node.js にせよ考えていない。
とはいえ、それでも HTTP をリクエストするという API においては、ブラウザにせよ Node/deno にせよ必要な API であり、どちらも表向きでいいから同じ API が欲しいというのは理解できる。ただし表向き同じ API というのがどこまでを指していっているのかが、Node.js / deno コミュニティ内で深く考えきれていない気がする。単純に似たようなものであれば、 Next.js でも提供されているし、 unfetch などの 3rd party 製のものもある。 Node.js のコアチームは undici と呼ばれる HTTP クライアントを次の HTTP クライアントとして提供している。
※ ちなみにマニアックな話になるが、 deno の fetch は ALPN を使った HTTP/2, HTTP/1.1 のネゴシエーションをしてくれるが、上述した Node.js のライブラリはどれも ALPN でのネゴシエーションはしてくれない。
fetch の中身を見ずにただ「fetchという表向き同じAPI」を指して、 fetch をコアの中に入れようとするとその「表向き同じ実装をどこまで頑張るのか」のコンセンサスを取るのに難しいし、既存のエコシステムを壊さないように入れるのは非常に時間がかかる。
筆者は fetch が一番複雑な思いを抱いている。現状の Node.js の http クライアントはブラウザのクライアントとはノリが違いすぎるので、気軽に call できる新しいクライアントはほしい。一方でブラウザがブラウザのために作った API と同じ API が実装されることは表向き良いとは思うものの、実際使ってみたら無意味な設定や設定しているつもりでも動かない機能が多くなり、結果として Bad Parts になってしまわないかという懸念はある。特に fetch は前述の simple か easy かという議論で言うと、 easy 寄りの API として提案されているように思える。 URL を fetch 関数に渡せば Promise で response が返ってくるという仕様は非常にわかりやすいが、実際には fetch クライアントが中でやっている処理は非常に複雑になっている。ブラウザが実装するものとしてはセキュリティに配慮した形でこのような API になることも理解できる。一方で、サーバサイドで呼び出す時にこの API がマッチしているのかに関しては、まだそこまで検討が進んでいないと思う。
自分が isomorphic だとか universal だとか言ってきた頃より時代が進み、同様なものが実装されるようになってきた。これ自体は良い兆候であると思う。一方でどこまで行っても「表向き同じもの」であって、細部がどこまで表現されているかはドキュメントには書かれていないことが多い。どこまで実装されているのかはもう少しドキュメントに書かれてほしい。
その他
これ以外にも clipboard API とかを実装したり、 navigator にあるようなクライアントの情報が取れる API を実装したりしようとしている issue も見かけたが、サーバサイドで実行された時にセキュリティホールになりそうだと最初に思ってしまった。基本的にブラウザのセキュリティモデルとサーバサイドで動くことが基本のプラットフォームとは同じ感覚で考えすぎるのは良くないと思っている。 deno にはパーミッションで防げる仕組みがあるとはいえ、サーバサイド内で実行されて困るような API を実装するべきではないと思っている。
まとめ
これまでは同じ API が増えることが Web というエコシステムを後押しするように思えていた。一方で、なんでもやりすぎるのはどうなのかと一旦立ち止まって考えるようになってしまった。特に atob/btoa を実装した辺りが個人的に立ち止まって考える切っ掛けになった部分だ。 Web Platform Test のカバレッジが増えることが良いことのようにされ、 mdn 上にある星取表が Yes になることが良いことだと思われているが、一方で、本当になんでも入れるのが良いことなのかについては考えていくようにして、フィードバックしたい。
2020年振り返り
はじめに
yosuke-furukawa.hatenablog.com
今年もちゃんと書きました。
マネジメントとシニアソフトウェアエンジニア
二足のわらじで4年目になりましたね。去年も書いたんですが、メンバーが優秀であるがゆえに二足のわらじができていると思っていて、それを4年目も継続できました。新しく何名か入ったおかげで非常に強力なフロントエンド体制ができてるなと思っています。
上記のブログは技術ブログの方に書いてもらったやつですが、他にも CodeZine や @IT 等に記事にしてもらっています。
関連会社の技術顧問
また去年から新しくリクルートの関連会社のニジボックスの技術顧問として活動していますが、そこでもエンジニアコミュニティを作って活性化させようとしています。
頼りになるメンバーが自組織の成長だけではなく、関連会社全体にも広げることができたので、これをより成長させていかないとなと思っています。
社内イベント
R-ISUCONを開催、スピードハッカソンも同時期に開催しました。ギリギリ COVID 19 が本格化する前だったのですが、どちらもオンラインではなくやりました。開催できてよかったですが、これから COVID-19 が本格化した影響でイベント系は予定がすべて一旦延期になりました。なので、開催できたのは2つだけです。
R-ISUCON 2020 を開催しました。
社内ISUCONも開催3度目で、今回はWebメールがお題でした。これがきっかけ(?)で、本家の ISUCON でも運営になる機会をもらえました。ISUCONについては後述します。
スピードハッカソンも開催しました。
イベント
コロナの影響で早々に JSConf は開催を断念しました。
yosuke-furukawa.hatenablog.com
しかし、 ISUCON は運営側としてオンラインで開催できました。オンライン開催する話も増えてるので来年は JSConf.jp やりたいです。
ISUCON 10 の予選に運営として参加した。
ISUCON 10 の予選を作成しました。予選の問題はある程度コンパクトでありかつチャレンジングな課題を設定できたと思っています。非常に好評だったのでよかったのですが、運営がはじめてということもあり、色んな人に迷惑をかけてしまったな、という反省は反省でありました。
ただ参加して本当に良かったと思っています。 941 さんとも色々話した結果はこちらに掲載されています。
登壇系
AMPFest 2020 に英語で登壇した。
AMPFest 2020 に英語で登壇する機会をもらえました。この話をきっかけに英会話を学ぶようになり、英語を再学習するきっかけになったのと、 AMPFest 2020 という大きな舞台でオンラインとは言え話ができて非常に良かったです。
Chrome Advisory Board のメンバーとして LT を実施
こちらも英語で登壇しました。年に2回も英語で発表するきっかけをもらえてよかったです。
継続して来年もどこかでやりたいですね。2019年のふりかえりで書いたことがこんなに早く叶うとは思ってなかったのですが、きっかけになってめっちゃ良かったです。
DevSumi 2020
デブサミ2020でクッキーの話ししました。ブラウザの中ではプライバシーが非常にホットなトピックでしたね。
FEStudy 2
パフォーマンスチューニングの話をしました。 Web Vitals 周りの話だけだともうたくさんされているので、それをキープするために考えることや対処することをまとめました。
PWA Study
Next.js と AMP のはなししました。 Next.js はほんとに今年かなり大きなプラットフォームになりましたね。
競技プログラミング
全体的にイベントがそこまで多くなかったので、それを逆手に取ってインプットに回ることができました。インプットを全力にやった結果を以下のブログにまとめました。競技プログラミングを割と本格的に入門できました。今年は JavaScript で解いてしまったのですが、来年は Rust とか新しい言語でも挑戦してみます。
yosuke-furukawa.hatenablog.com
yosuke-furukawa.hatenablog.com
Node.js
あまり大きな話題は少なかったのですが、いくつかアウトプットしました。
Node.js v14/v15 のまとめ
新機能系
yosuke-furukawa.hatenablog.com
yosuke-furukawa.hatenablog.com
英語
ほぼ毎日英会話50分間してます。ただあまり語彙が増えてない気がしているので、ちょっと他のチャレンジも考えてみます。

数学
毎日 Youtube の問題といてました。今でも解いてるので続けます。
もう少しやらなきゃなぁと思ってたけどできなかったこと
今回ベーシックな競技プログラミングや英語や数学やってたらできなかったですね。もう少し来年は上記のところもバランス良くできるように頑張っていきます。
まとめ
今年もマネジメントにプログラミングにイベント開催に登壇にと色々やれた1年でした。非常に充実していたのですが、反省もありました。また来年も自分の反省を乗り越えて色々できるように精進していきます。今年お世話になった皆様ありがとうございました。