2023年の振り返り
今年の漢字を一字上げるとしたら、筋トレの「筋」か受験の「験」かなと思います。 基本的に娘の受験勉強を見てあげるか、筋トレするかで過ごしてきました。 というのも今年が受験最終年で、筋トレは新しく趣味として始めてみたらハマってしまったというのが理由ですね。
一年前にやり始めた分割法で一年間続けた感じになります。筋トレはプログラミングとは違いますが、集中して何かに打ち込む事という意味では非常に良い趣味だなと思ってます。健康になりますし。
ただぶっちゃけ、受験勉強教えてから諸々やったあとに筋トレに行くと大体0時を過ぎており、筋トレのし過ぎで寝不足という健康なんだか不健康なんだか分けの分からない意味不明の状態になってるので、来年は睡眠をちゃんと確保しながらその辺りの事をできるように効率よくやっていきたいと思います。
それでは振り返ります。
yosuke-furukawa.hatenablog.com
仕事
今年ずっと考えていたのはサービスの存続や売上の確保と技術者のモチベーションの維持をどうやって両立させるかという点でした。面白い(≒技術者のモチベーションの上がる)開発をすることが必ずしも会社の繁栄に繋がるわけではなく、どちらも両立させるべきだという青い意見を昔は持ってましたが両立させることの難しさを痛感している日々ですね。
そんな思いを抱くうちに SPACE フレームワークとかの考え方に出会い、理論として学びながら自分の中でどうやって両立させるかを考える日々を送っています。
と、まぁそれはそれとして、フロントエンドエンジニアとして仕事でホットワードだったのは「App Router」って言葉かな〜と思います。どこ行っても聞くし、なんか色々と実践して試したりしてました。でも今のところ理念は理解できてもOSSとしてのissueや品質的な面で安定してないなという印象です。まだプロダクションで試せても小さなプロダクトがメインでしたね。
来年はもうちょい信頼できる品質になるだろうと信じてます。
ちなみに、メンバーがホント優秀で、 App Router もほとんどメンバーに教えてもらってましたね、ブログも彼らが勝手に何も言わずとも書いてくれるので助かってます。
イベント開催
JSConf.jp 2023
オフライン開催できました。もーオフラインで開催とか大変ですけど、みんなが現地で話してるのを見てると嬉しくなりますね。来年もやりたいなという思いを新たにしました。もうちょい効率的にできないもんかなーと思ってて、「人に仕事として依頼する」というのを覚えてきたのと過去2回のオンラインイベントで多少キャッシュが溜まってるのでそれをうまく使えるといいなと思ってます。
プレイリストはここで全部見れます。
JSConf JP 2023 Track A - YouTube
JSConf JP 2023 Track B - YouTube
JSConf JP 2023 Track C - YouTube
JSConf JP 2023 Track D - YouTube
雰囲気はこんな感じでした。
Good Bye Japan ❤️
— Aakansha (@aakansha1216) 2023年11月26日
Had really an amazing experience speaking at JSConf Japan and visiting the beautiful Japan✨
Kudos to the team for organising a great event!
どうもありがとうございます🙏 and I would definitely want to come back next year!#jsconfjp pic.twitter.com/tdGj7DhrdI
ちなみに 2023 一番変わったのはロゴでした。
https://t.co/dSAQzDNFtY の minor version up point
— Yosuke Furukawa (@yosuke_furukawa) 2023年11月18日
ロゴhttps://t.co/ckuFsqzVU7 pic.twitter.com/s51cqhc01i
せっかくオフラインで開催する機運が上がってるのに、タダメシを食べるとか、会場の受付を強行突破するとかの犯罪行為が勉強会の会場で行われてから周囲のオーガナイザーがピリピリしていて、ほんと気分が滅入りますね。犯罪まで考慮しないといけなくなってるのが辛いですね。こういうことやられるとイベント開催しようかなって人が減っちゃうし、嫌になりますね。
まぁそれでも来年もやりたいなと思います。
TC39 x JSConf talk event
実は一番個人的には結構話ができて嬉しかったのはTC39のイベントでしたね。
パネルディスカッションで話したかったことが話せてよかったですね。ESM と CJS の話も僕はもう「何が悪かった」というフェーズは終わり「次どうするか」を検討するフェーズになったなと感じました。来年またこういうのができるといいんですけどねー。
Node学園
今年は一回だけだったなー。やっぱ難しいな。こういうコンスタントに開くのは。
この回は書籍紹介の回で本を書くときの心構え的なのを話せてよかったですね。
登壇系
今年は割と抑えめに話しました。というのも結構エンジニアリング業務よりも家庭にパラメータを振っていたためです。
Next Web Conference 2023
登壇しましたねー。楽しかった。 登壇も楽しかったけど、始まる前にyoshikoとsakitoとかmyakuraさんと裏でワイワイ話したのが結構楽しかったですね。8割しょーもない話ししてたけど。
おわった〜〜〜〜めちゃ楽しかった!!!
— よしこ (@yoshiko_pg) 2023年12月16日
話したかったこと全部話しきれて、新しい発見も色々とあって自分的には120点の内容でした ☺️
お話しいただいた皆様 @yosuke_furukawa @herablog @koba04 と聞いてくれた皆様ありがとうございました🙌
帰ったらtogetterまとめます!#nwc_frontend_architecture
Deno Fest
Node.js の作者である Ryan が来て発表してくれた上に、僕がその次の発表という大役を任されて発表させてもらいました。楽しかったなー。
Findy Online Conference
キーノートスピーカーとして話させていただきました。普段から生産性とか仕事と直結した話だったので話しやすかったですね。その後の対談も楽しかった。
Developer Experience Day 2023
(こんな話ばっかしてるな。。。)CTO協会主催のイベントにも呼んでいただきました。
ジャムスタックチョットデキルカンファレンス 2023
Vercel の人もいる前で釈迦に説法してきました。
執筆系
Code Grid
Node.js についての記事を今年も書きました。毎年書いてて今年はほんと書くこと無いなーって思ったんですが、逆に書くこと無いなら深く「なぜこの機能が追加されたのか」とかそういう背景をたくさん書いてみました。そしたら編集からかなり評判が良かったので良かったです。
本
書いてます。毎週書いて進捗を出してます。来年には出せるといいな。
Blog
全然駄目でした。。。来年はもっと書きたいけど、一回中学受験を終わらせたい。
その他プログラミング系
一回休み。中学受験を(以下略
英語
がんばってやってるんだけど、あんまり時間が取れなかった。

まとめ
- 筋トレめっちゃ頑張った
- 中学受験をめっちゃ頑張った(来年成就させたい)
- 登壇と執筆がメイン
- それでもイベントは開催した、来年も開催する
- 仕事はどんどん経営寄りになり難しくなってきた
今年も楽しかったな。来年も頑張るぜ。
Node.js にプロセスレベルの Permission が入りそうな話
Node.js の Permission についての解説を行います。
Node.js に Permission 機能が入りそう。
すでに PR が出されており、 land も間近です。おそらく次かその次くらいのリリースで入ることになるでしょう。
おそらく初期リリースでは experimental flag を付けた上で、 fs, child_process, worker のパーミッションを許可するかどうかに留まり、 net, env などのパーミッションは今後になるでしょう。 以下の方法で利用します。
// filesystemの読み書きを許可する
$ node --experimental-permission --allow-fs foo.mjs
- --allow-fs ファイルシステムの読み書きを行えるようにする
- --allow-fs-read=
に記載のファイルパスの読み込みを行えるようにする *を書くと全パス許可 - --allow-fs-write=
に記載のファイルパスの書き込みを行えるようにする *を書くと全パス許可 - --allow-child-process 子プロセスの起動を行えるようにする
- --allow-worker ワーカースレッドの起動を行えるようにする
この時点ではプロセス単位でのパーミッションとなり、フラグを付与したらプロセスレベルで有効・無効が検知されます。 プロセス単位でのパーミッションは Deno なども戦略として取っているものです。
ただし、この機能自体は実際には 4 年以上前、 Deno が登場する前から議論として存在していました。
このときは関心がまだ少なく、実装するにも議論の土台となる話ができる状態になってなかったです。
Denoなどの競合や後述するサプライチェーンアタックの状況に対して、満を持して4年の歳月を経た後に Node.js に入れることになった経緯やパーミッションについての考え方を解説します。
Node.js において Permission の機能が必要になった背景
Node.js はかなり色んなツールで使われるようになりました。サーバサイド、クライアントのビルド、デスクトップアプリ、今やフロントエンド領域では使ってない所の方が珍しいと思います。一方で、例えば適当に作ったはずのアプリケーションのライブラリの奥の奥にあるライブラリが乗っ取られて悪意のあるものに書き換えられていたらどうなるでしょう。例えば npm に名刺を登録し、 npx @yosuke-furukawa/card とやると名刺が実行されるものがあります。
これを何の気なしに実行したら名刺としての公開情報が出るだけですが、この中のライブラリに .ssh の中身を読み込むものがあって秘密鍵を送られるなどの被害があるかもしれません。
この手の問題は開発者のワークフロー内に攻撃を仕掛けるため、開発からリリースまでの一連のサプライチェーンに対して攻撃をするという意味で「サプライチェーンアタック」と呼ばれており、近年盛り上がっている問題の一つです。
こういう問題は問題が顕著になると対策が取られます。ブラウザも Spectre, XS-Leaks などの問題が顕著になった事で様々な対策が取られてきました。 Site Isolation や Cross Origin Resource 制限系の対策は最たる例でしょう。サプライチェーンの問題は Node.js では大きく問題として受け取られてきました。そこで Permission の機能が検討されています。
Node.js の Permission を入れる時の方向性
Node.js はエコシステムが既にあります。このエコシステムを壊すことはできないため、既に存在する機能に対してオプトインする(後から付け加える)形で導入する必要があります。(この点、 Deno などの後発は Secure By Default としてデフォルトからセキュア側に倒す事もできる設計になっていますし、Denoは実際にそうなっています。)
また、プロセス単位の粒度で制限できることになります。
ちなみにプロセス単位の制御で良いのかという議論もあります。例えばモジュールレベルだったり任意の関数レベルのスコープで粒度を決める判断もあります。 しかしながら、これをやろうとすると既存のモジュールの作りに大幅に影響が出るので、最初ある「エコシステムを壊さない」に抵触するため、実際にはプロセスレベルの粒度ですすめることになりそうです。
つまり方向性としては、
- プロセスレベルでの制御に留める
- エコシステムを壊さない
という方向で進めようとしています。筆者は初期実装でやるレベルとしては妥当かなと思っています。
API レベルでの制御
また、この他にもAPIレベルで制御することができます。
process.permission.deny('fs'); // fs 処理を全部拒否 process.permission.deny('fs.write'); // write のみ拒否 process.permission.deny('fs.read'); // read のみ拒否 // 特定のフォルダだけ拒否 process.permission.deny('fs.write', ['/foo/bar/protected-folder']); process.permission.deny('fs.read', ['/foo/bar/protected-folder']);
また has で拒否したかどうかを確認できます。
process.permission.has('fs'); // true or false
注意事項
Permission は現時点では以下の注意があります。
- ネイティブモジュールは制限を受けない
- CLI では絶対パスだけ採用される、 API では相対パスも許可
- 子プロセスにはパーミッションが引き継がれない
- 子ワーカーにはパーミッションが引き継がれない
- 既に開いてしまっているリソースには制限が適用されない。できればリソースを利用する前に定義する必要がある。
最後のやつだけわかりにくいので解説します。
import fs from "node:fs"; const fd = fs.openSync("/foo/bar", "r"); // open した後に拒否する process.permission.deny('fs'); // この場合はエラーにならず、普通に読み取れる console.log(fs.readFileSync(fd).toString());
ルールが適用されるのは開く前の段階なので、使うなら open の前に書く必要があります。
// ここで使えばエラーになる。できれば、ステートメントが実行される前に事前に定義するほうが望ましい。 process.permission.deny('fs'); const fd = fs.openSync("/foo/bar", "r");
筆者のスタンス
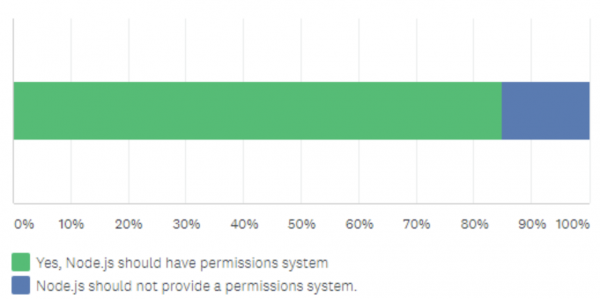
experimental なので使ってみることはあれど、中々使うのが難しい機能だなと感じます。一方コミュニティは Permission の機能に関して「あるべきである」とする vote が多かったので、コミュニティの声を反映して追加されています。 実際にコミュニティが全体的に使うのかどうなのかはわかりません。
先行実装している Deno 等で制御しても不便になり、結局全てを allow している状況を見たりすると、「権限を適切に管理するという事自体が人類には早すぎたのかもしれない」、そんな思いを抱いています。
ちなみに Deno で開発している人の意見として、「ローカル開発では "--allow-all" だけど、本番ではちゃんと権限設定してる」という意見も見ました。
これに関しては、本番環境の場合、 OS のプロセス実行ユーザー権限でファイルアクセスを縛ることもできるし、インフラ環境次第ではリクエストフィルターによって outbound のリクエスト先を制限することもできるので、本番環境の場合では、この機能はそこまで効果的なのか不明です。多層的にシステム全体とOSとプロセスの全てで防御したいという事であれば理解します。
ただ、実際には「ローカル環境でもサプライチェーンアタックの危険性は防げないといけない」と思っています。
一方で、選択肢が増えること自体は良いことのように思えています。これから開発する時に多層的な防御機構を使って開発できるというやり方が新しく加わることになります。 コミュニティ側で使ってみて、積極的にフィードバックできるところからしていければと思っています。
もしかしたら、人類には早かったかもしれませんが、 AI とインテグレートされた近未来の開発では勝手に AI が npm 実行時に必要な権限を...みたいな妄想をしつつ、一旦ここまでとします。
2022年の振り返り
今年は40歳になりまして、もういい加減健康とかにも気を使っていかないとなと思ったので、今年のテーマは「健康」でした。
結果として、
- 体重16kg落とした
- 筋トレ始めて4kg増えた。トレーニング器具を買った。
- 会社で筋トレ仲間を集めて合トレしている
って感じですね。
何やったか振り返ってみます。
健康
今年の1月に体重が歴代ハイスコアを記録してしまったので、本気でやばいと思ってダイエットを始めました。 具体的には、最初にKPIを体重に設定して、BMIが22を切るようにしました。
30分間ランニングを毎日実施してたのと、食事制限、糖質を少なめにしてました。具体的には昼食以外は炭水化物・糖質は取らないようにしていました。10月で16kg減できました。去年の自分の JSConf.jp 動画でのキャプチャと今年を比較すると多少痩せてることがわかりやすいかもですね。


ただこれだと体重は落ちていくんですが、周りから痩せ過ぎじゃない?と言われるようになったので、10月で方針変更して筋トレに向き合ってみました。 40年間生きてきて初の筋トレに向き合うというタイミングでした。
肩・背中・胸・腕・脚をそれぞれ分割して鍛える分割法とかEAAやプロテインを飲んだりと、そういうのを中心に2ヶ月間筋トレしております。10月時点でダイエットではなく、PFCバランスを見て、ちゃんと筋肉をつける食事に切り替えています。
結果として、体重は増えましたが、体脂肪はそこまで変わらずに4kgほどつけられました。もう一回ダイエットしたらいい感じになりそうですね。40年間筋トレと無縁だといきなりムキムキにはなりませんが、ここからもう少し頑張ろうと思いました。
それはそれとして
健康はすべての資本だとおもっていますが、それ以外も振り返りますね。
yosuke-furukawa.hatenablog.com
仕事
マネジメントとエンジニアの2足のわらじも継続しながらずっとやってます。最近はこれに「経営」的なものが加わりつつあり、大変ありがたいのですが、エンジニアとして名乗り続けるのは厳しくなってきていますね。何かのアプリケーションを生み出す形で貢献するのができていないなぁとは感じています。
まぁ自分のやってる仕事もやりがいがあるので特に焦っているわけではありませんが、何かしらの形でアウトプットはしていきたいと思っています。
経営も関わるようになって、つくづくミクロ的なものの見方をどうしてもしてしまう癖のようなものがあるなぁとは感じつつ、それも一つの武器として捉えられるようになりたいなと思っています。
悩みも含めてこんな発表もしていました。
それはそれとして、最近Next.jsとかTypeScriptでわからないことを検索するとだいたいメンバー記事がヒットしていて、メンバーの活躍がすごいなーと思ってます。つくづくメンバーに恵まれているのを感じます。
イベント開催
JSConf.jp
JSConf.jp 2022 を開催しました。
トラックごとに分割してアップロードもされているので、最新のキャッチアップをしたいという方がいれば、是非見てみてください。
来年はオフラインを開催したいと思っています。なるべく前半に、少人数でやってみようかなと。
東京 Node 学園
今年も3回開催しました。
来年もちゃんとやります。目指せ、100時限目
社内イベント
エンジニア系のオンラインイベントを会社の名義で実施していました。 JSConf.jp や 東京 Node 学園はどちらかというと技術に全振りしてますが、せっかくなので、技術以外の組織論的な話も入れた別角度からの話を触れてみました。どのトークも楽しかったです。
登壇系
今年もたくさん登壇したなぁという印象です。
Techfeed
毎回呼んでいただき、本当光栄です。特にテックフィードカンファレンスは大きいイベントということでやりがいがありましたね。
TechFeed Conference
TechFeed
PTA で発表
ちょっと変わり種ですが、PTAの成人教育委員会でも発表しました。小学校で新しくプログラミング教育が始まるということでどういう状況なのかを整理し、プログラミングを学ぶこととプログラマーになることを中心に話させていただきました。
podcast
fukabori.fm で楽しく話させていただきました。楽しかったです。ポッドキャストの登壇はなにげに久々でしたね。
Forkwell
Forkwell さんのイベントは potato4d さんとの対談ということでこれまた光栄でしたね。個人的には僕も悩んでいたような悩みだったので共感しました。
Blastengine
スクリプト言語のそれぞれの進化について話させてもらいました。
Findy
Toricls さんとの対談ということで、キャリア論について話させてもらいました。
Developers Summit (DevSumi Career Boost)
年末なので(?)、一個くらいはエモい話があってもいいかなと思って、キャリア論について話させてもらいました。
Node 学園
Bun についての話をしました。手前味噌ですが。
執筆系
CodeGrid
Node.js についての記事を今年も書きました。毎年書いてるとなんとなく追う側も深く追う癖みたいなのがついてきて良かったなと感じます。
Blog
今年こそは、、、と思って書いてたんですが、だめでしたね。もっと書きたかったけど、年末忙しくてペースダウンしました。
盛り上がったエントリ
yosuke-furukawa.hatenablog.com
力作だけど盛り上がらなかったやつ
yosuke-furukawa.hatenablog.com
この他にも
まだ何もアウトプットは出せてないけど、書き続けている本があって、それがリリースされるまでペースはこんなもんかもしれないです。がんばります。
競技プログラミング
今年は AoC は参加せず。途中で執筆と登壇で忙しくなりストップしました。一方でLeetCodeはほそぼそと続けてました。
LeetCode
とうとう1000問を超えました。もはや惰性で解いてて、逆に辞め時がわからないけど、たまに楽しい問題とかあるから解いてる感じですね。他のチャレンジをしてみます。

Github
ほそぼそと毎日コミットしています。もう数えてないけど、1000日以上コミットしてると思いますね。
英語
DMM 英会話しかやってないけど、最高ランクのレジェンドレベルになりました。

とはいえ、まだまだレベルは下だと思っており、「こっからもっと上げるのってどうすればいいと思う?」って素直に講師に聞いたら「サバイバルモードが足りてないのかもね」と言われてしまい、考えるようになりました。「サバイバルモード」というのは、「英語できなきゃ死ぬ」くらいのサバイバル条件で脳に対して刺激を与えるのが良いだろうというアドバイスですね。要は海外に住んでみるとかですかね。
まとめ
- 健康に気をつけて体重を絞り、筋肉をつけた
- 登壇たくさんした、podcast 楽しかった
- イベントで JSConf.jp / Node学園 / PostDev といろいろやった
- 執筆中の大作があるので、もうちょい忙しそう
- 競技プログラミングは1000問超えてしまった
- DMM英会話もレジェンドレベルに到達
次何やろうかなぁ。。。とはいえ、チャレンジも本書いたり、動画で説明するやつとかもやってるのでできていると思っており。もう少しエンジニア的な方面で Rust 使ってなにか作りたいなーと思いながらできていないので、その辺りが心残りですね。子育てしつつ、手を広げながらやれると良いなと思っています。
そういえば、ここに書いてない変化で言うと、車買って行動範囲が広がったのも良かったです。車の運転も慣れてきました。2023年はもう少しリアルな交流を増やしていきたいですね。ではでは。良いお年を。
Node.js fetch の内部の話
前置き
この記事は リクルートエンジニアアドベントカレンダーの3日目の記事です。
Recruit Engineers Advent Calendar 2022 - Adventar
ちなみにココで書いたやつを一部抜粋させていただいております(ネタ切れにより過去投稿を利用してしまっております。。。すいません。。。)
fetch が Node v18 から試験的にサポートされた
ブラウザでは数年前から採用されていた HTTP リクエストを行う関数の fetch が global 空間に関数として作成されました。使うだけなら特に何のフラグもいりません、その代わり使うと Experimental であることを知らせる Warnings が出ます。
// fetch.mjs const response = await fetch('https://api.github.com/users/github'); const data = await response.json(); console.log(data);
$ node fetch.mjs
(node:30917) ExperimentalWarning: The Fetch API is an experimental feature. This feature could change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
{
login: 'github',
id: 9919,
…
created_at: '2008-05-11T04:37:31Z',
updated_at: '2022-04-08T10:02:08Z'
}
この対応により、 Node.js 内部では長らく未サポートだった fetch が追加され、 node-fetch などのユーザーランドでの polyfill は不要になりました。一方で、 全ての fetch の仕様が実装されているわけではありません。そもそも、 browser 側の fetch には Node.js で実装しようにも Origin など、根本的な概念からして違うものもあり、100% 互換性のある実装は不可能です。そのため、試験的なサポートにまだとどまっています。
fetch の利用方法
fetch は上述した簡易的な GET リクエスト以外にもいくつかの利用方法があります。いくつか紹介します。
Agent をカスタム指定するケース
Node.js の fetch は Agent と呼ばれるクライアントを自分でカスタマイズする事が可能です。ブラウザの場合も細かくオプションに入れることで fetch の動きをカスタマイズできますが、 Node.js の場合はさらに強力に指定できます。例えばブラウザで HTTP/1.1 の場合、同じドメインに対して6接続までしか同時にアクセスできませんが、 Node.js の場合はこれを無制限にも、逆に1接続しか使わないようにもカスタマイズが可能です。他にも例えば、 HTTP 接続に対して keep-alive モードで接続することや keep alive の期間も細かく調整することが可能です。
import { Agent } from 'undici' const res = await fetch('https://example.com', { dispatcher: new Agent({ keepAliveTimeout: 10, keepAliveMaxTimeout: 10 }) }) const json = await res.json() console.log(json)
ただし、 一行目に書いてあるとおり、 fetch の dispatcher をカスタマイズするには undici ライブラリが必要です。 undici は後述しますが、 Node.js の HTTP クライアントの新しいライブラリです。将来的には Node.js の新しい HTTP クライアントに成り代わる予定のため、 undici はインストールしなくても良くなる予定です。
Web Stream / Node.js Stream を相互に利用するケース
Node.js には現状2種類の Stream が存在しています。 Web Stream と呼ばれる Stream と Node Stream と呼ばれるクラシックな Stream です。どちらも利用用途は存在します。 Web Stream は Promise が基本となっているため、 async/await で処理の流れを書いているプロダクトと親和性が高いです。 Node Stream は既存のエコシステムが Node Stream ベースで記述されている場合に有効です。
Promise と for await で書くと以下のようになります。
import fs from 'node:fs/promises'; const response = await fetch('https://example.com'); const readableWebStream = response.body; // write mode で file open する。 const file = await fs.open("./index.html", "w"); // for await 文で読み出しながらファイル出力する for await (const c of readableWebStream) { await file.write(c); } // 忘れずにクローズする。 await file.close();
また、 Node Stream を使った例ではこのように書くことが可能です。
import { Readable } from 'node:stream'; import fs from 'node:fs'; const response = await fetch('https://example.com'); const readableWebStream = response.body; // Web Stream から Node Stream へ変換する。 const readableNodeStream = Readable.fromWeb(readableWebStream); // Node Streamとして書き出す。 readableNodeStream.pipe(fs.createWriteStream('./index.html'));
POST で async iterator を利用する事も可能です。
const data = { async *[Symbol.asyncIterator]() { yield 'hello' yield 'world' }, }; const res = await fetch('http://localhost:3000/', { body: data, method: "POST"});
fetch の中身である undici について
Node.js では fetch は undici というライブラリに依存しています。 undici はイタリア語で 11 を示す言葉で、その名前の通り、 HTTP/1.1 のクライアントであることを示しています。逆に言うと、 HTTP/2 や HTTP/3 のクライアントとしてはまだ実装されていません。
そのため、 Node.js の fetch はブラウザの fetch とは異なり、 HTTP/2や3のネゴシエーションを行いません。こう聞くとなぜそんな中途半端な状態なのだろうと思うかもしれませんが、インターネット上に公開されている API ならまだしも、イントラネット内にあるバックエンドサーバへのリクエストでは HTTP で接続することも多く、 HTTPS が基本となる HTTP/2 や HTTP/3 は後で実装する運びになっています。
それよりもNode.js に新たな HTTP クライアントを用意し、インタフェースを他のランタイム (Denoなど) と揃えることをまずはターゲットにしたからという理由です。 ただそれ以外の部分では面白い実装になっている所も多いです。今回はそんな undici についても解説を進めます。
HTTP/1.1 クライアントの中身
HTTP クライアントがどう作られているかをそもそも知らないという方も多いと思うので、簡単に解説します。ここでは undici の内容についてということで HTTP/1.1 に限定した話をします。
HTTP クライアントは TCP と呼ばれるプロトコルからデータを受け取っています。接続方式とデータの受け渡しを決めているのが TCP で、HTTPはそのデータがどういう意味で使われているのかのセマンティクスを定義しています。特に開始行、ヘッダ、ボディ、トレーラーと言った4つの区分けされた部分を意識する必要があります。
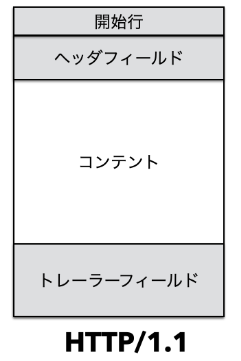
これらを区分けして中身を JavaScript で扱いやすくするためのものが「HTTPパーサー」です。 undici は主にこの「HTTPパーサー」で最適化が施されています。新しいクライアントを作るに当たって Node.js HTTP の既存ライブラリはイベントを発火しながら操作する事が前提となっていますが、余計な処理を省いて、完全に新規のライブラリとして書き換えたものとなっています。
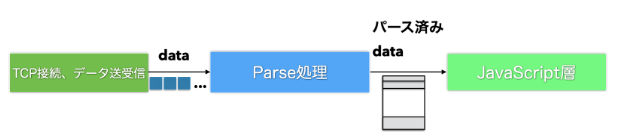
HTTP パーサーが WebAssembly になっている。
Node.js の HTTP パーサーはかなりユニークな仕組みになっています。このHTTPパーサーは TypeScript で書かれているのですが、コンパイルされて JavaScript になるのではなく、 C言語に変換されます。 llhttp というライブラリで公開されているので、内容を見てみたい方は下記の GitHub のリンクを見ていただけると良いでしょう。
https://github.com/nodejs/llhttp
Node.js は llhttp が出力した C 言語をそのままネイティブモジュールとして読み込んで使っています。 undici はここに一手間加えています。 C言語から wasm に変換した上で wasm として HTTP パーサーを利用しています。
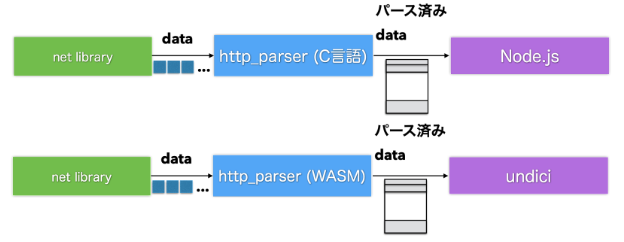
また、 wasm には simd 命令と呼ばれるベクトル演算に特化したCPU命令を試験的にサポートしています。これにより、並列実行されることを可能としており、パフォーマンスを飛躍的に伸ばしています。
Connections 1
| Tests | Samples | Result | Tolerance | Difference with slowest |
|---|---|---|---|---|
| http - no keepalive | 15 | 4.63 req/sec | ± 2.77 % | - |
| http - keepalive | 10 | 4.81 req/sec | ± 2.16 % | + 3.94 % |
| undici - stream | 25 | 62.22 req/sec | ± 2.67 % | + 1244.58 % |
| undici - dispatch | 15 | 64.33 req/sec | ± 2.47 % | + 1290.24 % |
| undici - request | 15 | 66.08 req/sec | ± 2.48 % | + 1327.88 % |
| undici - pipeline | 10 | 66.13 req/sec | ± 1.39 % | + 1329.08 % |
Connections 50
| Tests | Samples | Result | Tolerance | Difference with slowest |
|---|---|---|---|---|
| http - no keepalive | 50 | 3546.49 req/sec | ± 2.90 % | - |
| http - keepalive | 15 | 5692.67 req/sec | ± 2.48 % | + 60.52 % |
| undici - pipeline | 25 | 8478.71 req/sec | ± 2.62 % | + 139.07 % |
| undici - request | 20 | 9766.66 req/sec | ± 2.79 % | + 175.39 % |
| undici - stream | 15 | 10109.74 req/sec | ± 2.94 % | + 185.06 % |
| undici - dispatch | 25 | 10949.73 req/sec | ± 2.54 % | + 208.75 % |
https://github.com/nodejs/undici#benchmarks より抜粋 (2022年10月時点)
ただし、この結果はまだ実験中の WASM SIMD 呼び出しを利用した結果になります。実際にこのベンチマーク結果を得るためには「 --experimental-wasm-simd 」というフラグを付けて利用する必要があります。
# WASM SIMD を有効化しないといけない $ node --experimental-wasm-simd fetch.js
fetch の今後
fetch は WINTER CG と呼ばれる団体でランタイムエンジンそれぞれの仕様を固めようとしています。これにより、ブラウザの fetch ではなく、 JS ランタイムエンジンの fetch として仕様が定義されることになる予定です。もう少し噛み砕いて言うと、 Node.js / Deno / Bun / Cloudflare Workers などのランタイムエンジン上で共通の仕様を定義しようとしており、ブラウザの fetch の仕様に依存しない新しい fetch の仕様に改良しようとしています。

この fetch の共通仕様ができたら、それを実装する形で安定版としてリリースされる可能性があります。
Techfeed conference 2022 で Node.js 最新動向について話した
表題の通り話してきました。
本当は fetch の深い話とかもしたかったんですが、一応ライトニングトークということでほとんど話せなかった。なので、来月 Node 学園やる予定で、 v18 の話とか最近話題の WinterCG の話とか話したいなーと思ってます。 一旦今は予告的な感じ。詳しくは来月。
Node.js の原罪
Intro
ちょうどタコピーの原罪が流行ってるのでこのタイトルにしたけど結構気に入ってる。
この話を読んでの感想とここまで大きくなった Node.js の振り返りをしようと思う。
どんなプログラミング言語であってもみんなから使ってもらって開発者をハッピーにしたいと思ってる。ただ最初は良かったと思ってた機能がなんか古臭くなったり、他にクールな機能を持ったものが登場したことによって徐々に飽きられていき、最終的に他の言語に乗り換えられる。
まぁどんな言語も同じだと思う。C言語だって生まれた当初はすごくクールでみんなをハッピーにしてた。今丁度「戦うプログラマー」を読んでるが、C++が出てきて、周りのエンジニアが C++ を使おうとするシーンが出てくる。そこで、「あんなの使って何が良いんだ、Cで十分だろ」とWindows NT 開発リーダーのデーブカトラーが言ってたりする。ちょうどその頃(正確には NT リリースの少し後)に JavaScript も生まれている。
タコピーが特定の小学生を幸せにしたいと願ったように、プログラミング言語も開発者を幸せにしたいのだ。
それで言うと、 Node.js がここまで成功したことは喜ばしいことなんだと思う。個人的には 2013-2014年 くらいに Node.js やってますというと、「あんなの流行らないっすよねぇ」とか面と向かって言われたり、「いやーあんなネストが深くなる言語よく使ってるねー」とか言われたりしてたのが嘘のようだ。今はたしかに様々なクラウド環境、色んな場所で Node.js をサポートしてくれるようになっている。一方で何かが流行るという事は別な何かが廃れるという事でもある。 potato4d さんの書いた
いつから僕らは Node.js しか使わなくなったのか。 あれだけ話していた Rails などの多くの Web 技術にときめかなくなったのか。
これは Node.js が流行ったことで元々あった技術を振り返り「これでいいのだろうか」と自問をしているんだろうと思う。基本的にどんな技術であっても何かが流行る時は何かが廃れる時なのだ。
逆に言えば Node.js だっていつか廃れる側に入る。
これはまさに原罪なのではないか。永遠の命を生きることができたはずのアダムとイヴが知恵の実を食べた事で人はいつかは必ず死ぬようになったのと同じく、プロダクトやテクノロジーもいつかは必ず廃れるのだ。
つまり、「呪い」や「原罪」と書いたが、実はなんのことはない、数々のプロダクトやテクノロジーでは日常で起きている流行り・廃りという普通のことなのだ。
何がこの憂いの原因か
一方このポエムの中に流れる憂いのようなものもわかる。
真綿で締め付けられるように少しずつ、でも確実にロックインされていて、いつかそれの終焉が来た時に、自分の手元にあるものが「その技術」しかなかったらどうしようという焦燥感が感じとれる。 ものすごくよく分かる。ちょうど potato4d さんとは一度 1on1 を公開でしていたが、その時にも漠然とした焦燥感を感じた。
僕も同じような焦りはある。特にNode.js / フロントエンドの領域はどんどん作成するのが簡単になっていて、ちょっと前までは専門知識が必要になっていたことが、半年後には常識になっていたりする。コモディティ化してきている状況において、人材としての希少価値だったり、専門性みたいなものを追い求めようとすると常に最先端に居なきゃいけない気もするし、一方でそれだとロックインがどんどん進み、いつかこの技術が誰にでも使えるようなものになってしまった時、専門家としての自分の価値がなくなってしまう気もする。
ちなみに Deno に変えるっていう意見も見たが、あまり同意していない。徹底討論したときも思ったが、 Node.js と Deno は非常によく似た機能をどちらも有しており、多少の差はあれど、どっちも同じような所に落ち着きそうに思っている。 Deno は Node.js にとって破壊的なイノベーションではなく、持続的な改善だと認識しており、両者でキャッチアップして変わらない世界観の提供になると思っている*1。なのでまぁ、廃れる時は現代のフロントエンド技術そのものと共に両方廃れると思っている。
yosuke-furukawa.hatenablog.com
じゃあどうするのか
個人開発者としては開き直って使い続けててもいい。ここまで成熟して広まってしまうと延命措置もすごく長くなるし、どこかしらで使い続けられるだろうと思う。すぐに無価値になることはない。 一方で別に新しい技術を追うのも良い。どうあれ一個の技術だけで何でもできるような時代ではない。全然別な新しい技術が新しい革新を産んでいるんだな、と興味を持ったらやってみればいい。
正直どっちでもいいんじゃないかと思っている。
いずれにせよ、 Node.js などの技術 (Deno 含む) が現在の開発者を幸せにしているのであれば、ずっと追ってきた自分としては嬉しい限りだ。ここまで広まったのであれば、今後廃れたり、飽きられて終わってしまうならそれもまた良しと思っている。自分はまだ使えるうちは使っていくし、引き続き新しい機能が出たら紹介するといった動きを継続してやっていきたい。一方で、新しい技術を学ぶこともやめるつもりはない。 Go が流行ってる時に Go をやったり、 Rust が流行ってる時に Rust をやったりしてきた。なにか新しいことを吸収しては吐き出すという事を常にやろうと思っている。
こういう流行りにも乗っかりながら、今の自分の強みとなる技術を磨き続ける事が僕の中での最適解だ。
Node.js 年表
それはそれとして、メンバーとこの potato4d さんのブログ記事について色々話していたら、 Node.js でこういうポエムが書かれるのって昔と比較すると信じられないねっていう話になり、俺たちずっと追ってきたけど、良かったよねっていう話をして懐かしさに浸ってしまった。 今 Node.js が流行っている理由の一つは React や TypeScript による強固な仕組みが整ったことが要因だと思っているが、それが流行るまでの歴史的な年表作りたいなと思ったので、書いてみることにする。
| 年 | 出来事 |
|---|---|
| 2009年春 | Node.js プロジェクト始動、 Ryan Dahl が v8 にネットワーク I/O を組み込んだアプリケーションを作る。最初の名前は netv8 だった、(微妙に .Net 感もあったからなのか知らないけど) rename されて Node.js になる。 |
| 2009年秋 | Node.js を jsconf.eu で初公開、一気に注目を浴びる。 |
| 2010年 | Node.js が Joyent に買われる、 Joyent は Node.js を中心とした PaaS を作っていきたいという思いがあった、 Node.js は安定した収益のもとでコラボレーションしたかった。両者の利害が一致して買収された。 |
| 2011年 | 破壊と創造の時代、 API作っては壊し、破壊的変更が起きまくっていた。色々なライブラリが雨後の筍のように現れ、使われていった。 express / socket.io などがその筆頭。この頃に Node 学園祭も実施される、 Ryan Dahl が日本に来てた。 Guille (Vercel CEO)も来てた。 |
| 2012年 | いきなりここまで来たけど、破壊と創造の時代を終わらせて、Ryan がリーダー辞めますって言い出した。2代目リーダー (isaacs) に権限を移譲 |
| 2012年 | Node 学園祭で isaacs が新しい Stream とかの構想を発表、 substack が small module の話と unix philosophy の話をしていた。この頃から小さいモジュールをたくさん作って組み合わせようぜ的なノリになる。 |
| 2013年 | 2代目リーダーを中心に Stream 周りやエラーハンドリング (domains など) 周りで色々と新しいものが追加される。 |
| 2013年 | この頃くらいから grunt / gulp / yeoman などを筆頭に Node.js がフロントエンドのツールとして使われていく。 |
| 2013年 | ちなみにこの頃に Rendr というアプリケーションフレームワークが少しだけ脚光を浴びる、今の next.js などがやっている、ブラウザでもNodeでも動く、 Universal な フレームワークがここで登場。この頃から Node 学園祭で取り上げてた。 |
| 2013年 | 古川が 2 代目 日本 Node.js ユーザーグループ代表になる |
| 2014年 年初 | isaacs 氏がここに来て npm をちゃんとした会社にする、と言って、リーダーを抜けて 3代目に引き継いだ (TJ Fontaine) |
| 2014年 | この頃くらいから browserify などを筆頭に Node.js がフロントエンドの主にモジュール解決周りで使われだす。 |
| 2014年 | issue / PR がめちゃくちゃ停滞する。API の安定を求められたことといきなり引き継いだリーダーとして導くのが3代目では難しかったように思う。ここに来て、 Joyent という会社の中だけでリーダーを選出していたことが仇になった感じがある。いわゆる GitHub で "Is Node.js dead ?" って聞かれてしまうようなレベルで特に何も改善がないままズルズルと放置されてた |
| 2014年 | AWS Lambda が Node.js サポートで初期リリースされる。 |
| 2014年 年末 | Node.js が fork されて io.js が誕生する。 yosuke-furukawa.hatenablog.com |
| 2015年 年初 | BDFL を中心にした Node.js と コミュニティを中心にした io.js で分断が起きる、あっという間に v8 が最新になり、次々と新しい機能が出現した |
| 2015年 | io.js と Node.js の再マージ案が出る、このまま分断されるのかどうなるのかを見守っていた自分としてはマージされる運びとなり、一安心、 YAPC で顛末を発表したどうしてこうなった? Node.jsとio.jsの分裂と統合の行方。これからどう進化していくのか? - Speaker Deck |
| 2015年 | ES2015 が出て、 babel が支配的になり、トランスパイルに抵抗がなくなる。 React などのフロントエンドライブラリが大きく躍進する。この頃色んなカンファレンスどこも JavaScript の話ししてた気がする。 |
| 2015年 | electron とかが流行ってた。自分もなんかアプリ作って出したりしていた。 |
| 2015年 | isomorphic tokyo meetup 開催、 Next.js とかが話されるよりも前に、クライアントとサーバで同じ処理が動くようにすれば Node.js ってもっと面白くなるんじゃね?みたいな話ができてた。 |
| 2016年 | npm が勝手にライブラリを消したことで leftpad 問題と呼ばれる大きな問題が起こる、この頃から「俺たちなんかたくさんライブラリに依存しすぎじゃね?」みたいな雰囲気になる。 |
| 2016年 | ES Modules と CommonJS との相互運用についての議論が起きる。 yosuke-furukawa.hatenablog.com 入れる必要ある?いらなくね?いや、いるだろ、ブラウザと同じコード動かすかもしれないんだし、差は少ないほうがいい、みたいな議論がたくさん起きて、一回 Issue がクローズされる。その後、 TC39 や WHATWG を巻き込んだ議論になっていく。 |
| 2016年 | この頃にはもう browserify じゃなくて webpack とかでやるのが普通になっており、 React / Redux とかアプリケーションを作る方法も変化しながらも確立されていく。僕はこの頃、 React で SSR とか BFF とか言ってた気がする。今でも言ってるか。この年の ISUCON 本戦の問題が確か SSR だった気がする。 |
| 2016年 | Next.js がリリースされる。微妙にクエリーパラメータでしかルーティングできなかったので、この頃はそこまで流行ってなかったように思う。ただ React の SSR を基本にしたボイラープレートは雨後の筍状態でたくさんあった。 |
| 2017年 | Node.js に HTTP/2 を入れたり、 async-await が入ってたくさん色んな改善が進む |
| 2017年 | React で SSR やるとどうしても Node.js のプロセスが圧迫されるので、パフォーマンス・チューニング系の話が多かった気がする。 async_hooks などの非同期で状況をトレースできるようにする仕組みが入ったり、 Node.js にもパフォーマンス計測系の活動が行われてた気がする。 |
| 2017年 | ESModules の解決が Node.js でできるようになった。一方でブラウザ側はトランスパイルする事で形だけ ESM を使っているような状況であり、 HTTP/2 が入ったり色々な改善がブラウザに起きていたものの、 ESM が普通に使えるような状況ではなかった。逆に Node.js で先に実装が進んでしまった。 |
| 2017年 | 2016年くらいから TypeScript が VS Code とともに流行る。3rd party モジュールの型を解決する方法に決着が付いたことも大きかったように思う。 |
| 2017年 | Node.js内でWeb Community との親和性を上げていこうという動きがもっと活発になる。 async-awaitなどのパーツが揃ってきたことで、どんどんフロントエンド開発者にも使われるようになり、なるべく API を揃えようという流れに。 |
| 2018年 | Deno が jsconf.eu で発表される。 Node.js の10の後悔という内容でめちゃくちゃバズる。 yosuke-furukawa.hatenablog.com TypeScript で開発されており、ものすごく注目を浴びる。 |
| 2018年 | Node.js の性能やセキュリティ面、デバッグ可能性をあげていこうというものすごく下回りの整備がされていく。 http parser が llhttp になって、なんじゃこりゃーすげーってなったのを覚えてる。 |
| 2018年 | npm が資金難みたいな感じでなんか色々と開発者が辞めたり、レイオフにあったみたいな話が出てくる。ゴタゴタする。 |
| 2019年 | npm vs yarn 抗争激化、どっちも zero install とか言い出す。結果は・・・ |
| 2019年 | npm のレジストリを管理していた人たちが entropic という分散管理レジストリの構想を出す。結果は・・・ |
| 2019年 | React に hooks が入る。 Redux とかの状態管理周りのやり方が中央集権的なものからコンポーネントの状態へ、分散独立的な流れになった。 |
| 2019年 | Next.js が動的にパラメータを受け付ける書き方ができるように改善される、他にも Google のメンバーから色々とコントリビューションを受け付けるようになり、一気に大規模化する。自分もこの段階で Next.js を再評価した気がする。 |
| 2019年 | jsconf.jp 第一回目開催 |
| 2019年 | Node.js 10周年、ここらあたりで、「あーなんか Node.js って前よりも普通に受け入れられるようになってるんだなぁ」と実感する。 |
| 2020年 | COVID-19 pandemic になる、ほとんどのカンファレンスが中止、一気に色々とリモートワークに変わる |
| 2020年 | npm が github にジョイン、一旦資金難とか開発者不足は解消される |
| 2020年 | Deno v1.0 リリースされる。 |
| 2020年 | Node.js next 10 という次の10周年のためのマイルストーンが出てくる。 fetch / single executable app / ESM 強化 / TypeScript との親和性強化 などの進化が掲げられる |
| 2021年 | Node.js に Promise 化や AbortController など Web Standard との親和性に必要なパーツが徐々に揃ってくる。一方で、なんとなく Deno との競争意識からか、本当にいるのか不明なものも入ったりする。 btoa/atob とか。。。 |
| 2021年 | また少しずつフロントエンド周りの競争が激化する、特に webpack vs esbuild や remix vs next.js 、 deno vs Node.js などの競合と競争関係になる。新陳代謝の時期かもしれない。 |
| 2022年 | 現代へ。この記事書くの大変でした。 |
こうやって歴史的な年表を書いてみた(だいぶ自分の話もあるが)。けど、いつ流行りが終わるのか、それともまだまだこれからも続くのかという疑問に回答は出なかった。なんとなくだけど、身近な競合がまだまだ雨後の筍のように出てきている現状では廃れるという事はしばらく無さそうではあった。ただ数年後にはわからない。
いずれにせよ、振り返るのも面白かった。
*1:自分はそれが非常に残念である、 Deno が Node.js 互換を提供するとは言ってほしくなかった、ぜんぜん違う世界観を追っていてほしかった。
Node.js / Deno の徹底討論を Node 学園で行いました。
3/17 に徹底討論という形で denoland の 日野沢さん をお呼びして Node学園で徹底討論という形で討論しました。
いくつか面白いトピックがあり、参考になると幸いです。
少しだけ紹介します。
ESM vs CJS
ESM と CJS の対応が Node.js がグダグダだと思っていると言われた点がありました。
討論内でも Twitter を見ていても、そういう意見があって、意外だなーと思いました。
もちろん現実的に ESM / CJS の移行は今はまだ過渡期です。既存のエコシステムを壊さないために CJS との相互運用性を持ち込むしかなかったという状況においては現時点の拡張子やpackage.jsonでの指定で識別可能にし、既存のエコシステムを壊さないように乗り切ったというところはむしろ評価していました。この移行措置が無く、もしも Node.js v20 からは ESM でしかロードできないと言われた場合はどうなっていたでしょう。多分誰も v20 に上げられず、結局 v19 がLTSが終わるまで使い続け、LTSが終わったあともどこか (Red Hat とか) が 3rd party製の Node.js v19 のメンテナンスを名乗り出て、サポートし続けるといった悲劇が生まれていたように思えます。エンタープライズはそれで乗り切ろうとかそういう議論が行われていたでしょう。それがなかったとしても、 このモジュールはESM, このモジュールはCJSといったように自分で見分けるとかそういう事はやってられないと思います。結局 TypeScript でずっとトランスパイルして、 Node.js でも ESM ではなく、しばらく CJS で使われていたのではないでしょうか。
そう思うと非常に今の移行過渡期の状態というのはそこまでグダグダではないと思っています。
でもいま現実的にきついんだけど
それはそのとおりですが、それは Node.js だけのせい、というわけでもないように思えます。結局 ESM は CJS でロードされた JavaScript とは互換性がないものとして設計されてしまっています。むしろ Node.js は被害者で、そこで一定の互換性をプラットフォームとして保ちつつ、新しい仕様に追従していく、というのは非常に根気のいる作業です。個人的には新しく2つめのロード方法を作り直してしまって後はユーザーが選べば良いという位割り切ってしまってもよかったように思えますが、それをせず、どちらから呼ばれても動くようにするために、色々な仕様を TC39 とも調整し、 WHATWG 側にも話を聞きに行ったりしつつ、最初のPRから数年掛けて今の相互運用できる状況にまで達成したことは非常にすごかったな、、、と思っています。
xxx feature is bad.
よく JavaScript を見ていると、この機能が駄目だとか、この機能がイケてないという話をよく目にします。これだから JavaScript は、、、となってしまう気持ちもわかりますが、ちょっと調べてみると奥になんでその仕様になっているかの背景が結構語られています。その内容には歴史的な背景が紐付いていることが多いです。「ウッ」となって文句を書いたり言う前に何故そうなのかを調べてみると面白いと思います。
こういう話をたくさんしました。ぜひぜひ上の動画を見てみて下さい。